Einführung
Die neuronale Verarbeitung von Gesichtern ist ein weit erforschten Thema der kognitiven Wissenschaft. Basierend auf funktionellen Bildgebungsstudien, Einzelzellaufnahmen und neuropsychologischen Untersuchungen wurde vorgeschlagen, dass die Gesichtsverarbeitung über ein verteiltes Netzwerk erfolgt, an dem mehrere kortikale Bereiche des Säugetiergehirns beteiligt sind (Haxby et al., 2000; Marotta et al., 2001; Rossion et al., 2003a; Avidan et al., 2005; Sorger et al., 2007)., Während das Ausmaß dieses Gesichtsverarbeitungsnetzwerks derzeit intensiv diskutiert wird (Ishai, 2008; Wiggett und Downing, 2008), sind sich die meisten Forscher einig, dass es zahlreiche kortikale Bereiche gibt, die durch Gesichtsreize aktiviert werden. Das einflussreichste Modell der Gesichtswahrnehmung, basierend auf dem ursprünglichen Modell von Bruce und Young, 1986; Young und Bruce, 2011) schlägt eine Unterscheidung zwischen der Darstellung invarianter und varianter Aspekte der Gesichtswahrnehmung auf relativ unabhängige Weise vor, getrennt in einen „Kern“ und einen „erweiterten“ Teil (Haxby et al., 2000)., Die wichtigsten Regionen des“ Kernnetzes “ sind Bereiche des okzipitalen und des lateralen fusiformen Gyri (FG). Die Bereiche dieser beiden anatomischen Regionen scheinen auf unterschiedliche Aufgaben spezialisiert zu sein: Während der okzipitale Gesichtsbereich (OFA), der sich am unteren okzipitalen Gyrus (IOG) befindet, an der strukturellen Verarbeitung von Gesichtern beteiligt zu sein scheint, verarbeitet der fusiforme Gesichtsbereich (FFA) Gesichter auf höherer Ebene und trägt beispielsweise zur Verarbeitung von Identität bei (Sergent et al., 1992; George et al., 1999; Ishai et al., 1999; Hoffman und Haxby, 2000; Rossion et al., 2003a,b; Rotshtein et al.,, 2005). Darüber hinaus sind die veränderlichen Aspekte von Gesichtern (wie Mimik, Blickrichtung, Ausdruck, Lippenbewegungen) (Perrett et al., 1985, 1990) oder Lippenlesen (Campbell, 2011) scheinen im oberen temporalen Sulcus verarbeitet zu werden (STS; Puce et al., 1998; Hoffman und Haxby, 2000; Winston et al., 2004). Die drei oben genannten Bereiche (FFA, OFA, STS) bilden den sogenannten „Kern“ des Wahrnehmungssystems der Gesichtsverarbeitung (Haxby et al., 2000; Ishai et al., 2005)., Während grundlegende Informationen über Gesichter von diesem Kernsystem verarbeitet werden, fügen komplexe Informationen über die Stimmung, das Interesse, die Attraktivität oder die Richtung der Aufmerksamkeit der anderen Informationen zur Gesichtswahrnehmung hinzu und werden von einem zusätzlichen, sogenannten „erweiterten“ System verarbeitet (Haxby et al., 2000). Dieses System enthält Gehirnregionen mit einer Vielzahl kognitiver Funktionen, die mit der Verarbeitung veränderlicher Gesichtsaspekte zusammenhängen (Haxby et al., 2000; Ishai et al., 2005) und umfassen Bereiche wie die Amygdala, Insula, den unteren frontalen Gyrus sowie den orbitofrontalen Kortex (Haxby et al.,, 2000, 2002; Fairhall und Ishai, 2007; Ishai, 2008).
Wechselwirkungen der oben genannten Bereiche werden in der vorliegenden Studie mit Methoden modelliert, die die effektive Konnektivität zwischen kortikalen Bereichen berechnen. Dynamic Causal Modeling (DCM) ist eine weit verbreitete Methode, um eine effektive Konnektivität zwischen Gehirnregionen zu untersuchen. Es ist ein generischer Ansatz zur Modellierung des gegenseitigen Einflusses verschiedener Hirnareale aufeinander, basierend auf fMRI-Aktivität (Friston et al., 2003; Stephan et al., 2010) und um das Interverbindungsmuster kortikaler Bereiche abzuschätzen., DCMs sind generative Modelle neuronaler Reaktionen, die „a posteriori“ Schätzungen synaptischer Verbindungen zwischen neuronalen Populationen liefern (Friston et al., 2003, 2007). Die Existenz des verteilten Netzwerks für die Gesichtsverarbeitung wurde zuerst durch die funktionale Konnektivitätsanalyse von Ishai (2008) bestätigt, der behauptete, dass der zentrale Knoten der Gesichtsverarbeitung der laterale FG ist, der mit Bereichen niedrigerer Ordnung des IOG sowie mit STS, Amygdala und frontalen Bereichen verbunden ist. Der erste Versuch, das Gesichtsverarbeitungsnetzwerk bei realistischen dynamischen Gesichtsausdrücken aufzudecken, wurde von Foley et al. (2012)., Sie bestätigten die Rolle von IOG -, STS-und FG-Bereichen und stellten fest, dass die Verbindungsstärke zwischen Mitgliedern des Kernnetzwerks (OFA und STS) und des erweiterten Systems (Amygdala) für die Verarbeitung affektbeladener Gesten erhöht ist. Derzeit haben mehrere Studien unser Verständnis des Gesichtsverarbeitungsnetzwerks vertieft und einen direkten Zusammenhang zwischen Amygdala und FFA und der Rolle dieser Verbindung bei der Wahrnehmung ängstlicher Gesichter aufgedeckt (Morris et al., 1996; Marco et al., 2006; Herrington et al., 2011)., Schließlich wurde die Wirkung höherer kognitiver Funktionen auf die Gesichtswahrnehmung auch durch Testen der Verbindungen des orbitofrontalen Kortex mit dem Kernnetzwerk modelliert (Li et al., 2010). Es wurde gefunden, (Li et al., 2010), dass der orbitofrontale Kortex eine Wirkung auf den OFA hat, der die Informationsverarbeitung des FFA weiter moduliert.
Während frühere effektive Konnektivitätsstudien die Details des Gesichtsverarbeitungsnetzwerks in Bezug auf verschiedene Aspekte der Gesichtswahrnehmung enthüllten, ignorierten sie die einfache Tatsache, dass Gesichter auch als visuelle Objekte betrachtet werden können., Wir wissen aus einer großen Anzahl von Experimenten, dass visuelle Objekte von einem verteilten kortikalen Netzwerk verarbeitet werden, einschließlich früher visueller Bereiche, occipito-temporaler und ventral–temporaler Kortizen, die sich weitgehend mit dem Gesichtsverarbeitungsnetzwerk überlappen (Haxby et al., 1999, 2000, 2002; Kourtzi und Kanwisher, 2001; Ishai et al., 2005; Gobbini und Haxby, 2006, 2007; Haxby, 2006; Ishai, 2008). Einer der Hauptbereiche der visuellen Objektverarbeitung ist der laterale Okzipitalkortex (LOC), der in zwei Teile unterteilt werden kann: den anterior–ventralen (PF/LOa) und den kaudal–dorsalen Teil (LO; Grill-Spector et al.,, 1999; Halgren et al., 1999). Das LOC wurde zuerst von Malach et al. (1995), die im Vergleich zu Rührobjekten eine erhöhte Aktivität für Objekte, einschließlich berühmter Gesichter, gemessen haben (Malach et al., 1995; Grill-Spector et al., 1998a). Seitdem wird das laterale Okzipital (LO) primär als objektselektiver Bereich betrachtet, der jedoch immer auch für Flächen eine erhöhte Aktivierung aufweist (Malach et al., 1995; Puce et al., 1995; Lerner et al., 2001), insbesondere für umgekehrte (Aguirre et al., 1999; Haxby et al., 1999; Epstein et al.,, 2005; Yovel und Kanwisher, 2005).
Daher ist es ziemlich überraschend, dass sich zwar mehrere Studien mit der effektiven Konnektivität von Gesichtsverarbeitungsbereichen befasst haben, aber keiner von ihnen die Rolle des LO im Netzwerk in Betracht zog. In einer früheren fMRI-Studie fanden wir heraus, dass LO eine entscheidende Rolle im sensorischen Wettbewerb um Gesichtsreize spielt (Nagy et al., 2011)., Die Aktivität von LO wurde durch die Präsentation gleichzeitig präsentierter gleichzeitiger Reize reduziert, und diese Reaktionsreduktion, die den sensorischen Wettbewerb zwischen Reizen widerspiegelt, war im Vergleich zu einem randomisierten Fourier-Phasen-Rauschbild größer, wenn der umgebende Reiz ein Gesicht war. Dieses Ergebnis unterstützt die Idee, dass LO möglicherweise eine Besondere Rolle spielen in die offene Wahrnehmung. Daher untersuchten wir hier explizit mit Methoden effektiver Konnektivität, wie LO mit FFA und OFA verbunden ist, Mitgliedern des vorgeschlagenen Kernnetzwerks der Gesichtswahrnehmung (Haxby et al., 1999, 2000, 2002; Ishai et al., 2005).,
Materialien und Methoden
Probanden
25 gesunde Probanden nahmen an dem Experiment teil (11 Frauen, Median: 23 Jahre, min.: 19 Jahre, max.: 35 Jahre). Alle von ihnen hatten normales oder normales Sehen (selbst berichtet), keiner von ihnen hatte neurologische oder psychische Erkrankungen. Themen, sofern Ihre schriftliche Einwilligung in übereinstimmung mit den Protokollen genehmigt durch die Ethikkommission der Universität Regensburg.,
Stimuli
Die Probanden wurden zentral durch Graustufenflächen, Nicht-Sinnesobjekte und die Fourier-randomisierten Versionen dieser Stimuli dargestellt, die durch einen Algorithmus (Nasanen, 1999) erstellt wurden ersetzt das Phasenspektrum durch zufällige Werte (im Bereich von 0° bis 360°), wobei das Amplitudenspektrum des Bildes intakt bleibt, während Forminformationen entfernt werden. Gesichter waren digitale Vollfrontbilder von 20 jungen Männern und 20 jungen Frauen. Sie passten hinter eine runde Formmaske (3,5° Durchmesser), die die äußeren Konturen der Gesichter eliminierte (siehe Beispielbild in Abbildung 1)., Objekte waren nicht sinnvolle, gerenderte Objekte (n = 40) mit der gleichen durchschnittlichen Größe wie die Gesichtsmaske. Die Luminanz und der Kontrast (d. h. Die Standardabweichung der Luminanzverteilung) der Reize wurden durch Abgleich der Luminanzhistogramme (mittlere Luminanz: 18 cd/m2) mit Photoshop gleichgesetzt. Stimuli wurden über einen LCD-Videoprojektor (JVC, DLA-G20, Yokohama, Japan, 72 Hz, 800 × 600 Auflösung) auf eine durchscheinende kreisförmige Leinwand (ca. 30° Durchmesser), in der Scannerbohrung 63 cm vom Beobachter entfernt platziert., Stimulus Präsentation wurde über E-prime Software gesteuert (Psychological Software Tools, Pittsburgh, PA, USA). Gesichter, Objekte und Fourier-Rauschbilder wurden in nachfolgenden Blöcken von 20 s dargestellt, die mit 20 s Leerperioden verschachtelt waren (einheitlicher grauer Hintergrund mit einer Leuchtdichte von 18 cd/m2). Reize präsentiert wurden, für 300 ms und wurden gefolgt von einem ISI von 200 ms (2 Hz) in zufälliger Reihenfolge. Jeder Block wurde fünfmal wiederholt. Die Teilnehmer wurden gebeten, sich kontinuierlich auf eine zentral präsentierte Fixierungsmarke zu konzentrieren., Diese Functional localizer Runs waren Teil von zwei anderen Experimenten zur Gesichtswahrnehmung, die an anderer Stelle veröffentlicht wurden (Nagy et al., 2009, 2011).

Abbildung 1. Beispielreize des Experiments. Alle Bilder waren Graustufen, gleich groß, Leuchtdichte und Kontrast. Linke Seite zeigt ein Gesicht, geschlechtsspezifische Merkmale (wie Haare, Schmuck usw.) war hinter einer ovalen Maske versteckt. Mittlere panel zeigt eine probe nicht-sinn geometrische objekt, während rechte panel zeigt die Fourier-phase randomisierte version von objekten, verwendet als control stimuli.,
Datenerfassung und-analyse
Die Bildgebung erfolgte mit einem 3-T MR-Kopfscanner (Siemens Allegra, Erlangen). Für die Funktionsserie haben wir kontinuierlich Bilder aufgenommen (29 Scheiben, 10° geneigt relativ zur axialen, T2* gewichtete EPI-Sequenz, TR = 2000 ms; TE = 30 ms; Flip-Winkel = 90°; 64 × 64 Matrizen; In-Plane-Auflösung: 3 mm × 3 mm; Slice-Dicke: 3 mm). Hochauflösende sagittale T1-gewichtete Bilder wurden unter Verwendung einer Magnetisierungs-EPI-Sequenz (MP-RAGE; TR = 2250 ms; TE = 2) aufgenommen.,6 ms; 1 mm isotrope Voxel-Größe), um einen 3D-Strukturscan zu erhalten (Details siehe Nagy et al., 2011).
Funktionelle Bilder wurden für die Aufnahmeverzögerung korrigiert, neu ausgerichtet, auf den MNI-Raum normalisiert, auf 2 mm × 2 mm × 2 mm Auflösung resampliert und räumlich mit einem Gaußschen Kern von 8 mm FWHM geglättet (SPM8, London Department of Imaging Neuroscience, London, UK; Einzelheiten zur Datenanalyse finden Sie unter Nagy et al., 2011).
VOI-Auswahl
Zunächst wurden Interessenvolumina (VOI) basierend auf Aktivität und anatomischen Einschränkungen (einschließlich Maskierung für relevante Gehirnregionen) ausgewählt., Gesicht-selektive Bereiche wurden definiert als eine Fläche mit größerem Aktivierung für Flächen im Vergleich zur Fourier-noise-Bilder und Objekte. FFA wurde innerhalb des lateralen fusiformen Gyrus definiert, während OFA innerhalb des IOG. LO wurde aus dem Objekt Fourier-Rauschen und Gesichtsbilder Kontrast innerhalb des mittleren Okzipitalgyrus definiert. Die VOI-Auswahl basierte auf den mit F-Kontrast angepassten T-Kontrasten (p < 0.005 unkorrigiert mit einer minimalen Clustergröße von 15 Voxeln)., VOIs waren kugelförmig mit einem Radius von 4 mm um die Peakaktivierung (für einzelne Koordinaten siehe Tabelle A1 im Anhang). Die Varianz, die durch die erste Eigenvariate der Fettsignale erklärt wurde, lag alle über 79%. In der aktuellen DCM-Analyse wurden nur Bereiche der rechten Hemisphäre verwendet, da mehrere Studien auf die dominante Rolle dieser Hemisphäre bei der Gesichtswahrnehmung hinweisen (Michel et al., 1989; Sergent et al., 1992).,
Effektive Konnektivität Analyse
Effektive Konnektivität getestet wurde von DCM-10, umgesetzt in SPM8 toolbox (Wellcome Department of Imaging Neuroscience, London, UK) unter Matlab R2008a (The MathWorks, Natick, MA, USA). Modelle von DCM werden mit endogenen Verbindungen definiert, die die Kopplung zwischen Hirnregionen (Matrix A), modulatorischen Verbindungen (Matrix B) und Antriebseingängen (Matrix C) darstellen. Hier in der A-Matrix haben wir die Verbindungen zwischen den flächenselektiven Regionen (FFA und OFA) und LO definiert., Bilder von Gesichtern und Objekten dienten als Antriebseingang (Matrix C) und in diesem Analyseschritt haben wir keine modulatorischen Effekte auf die Verbindungen angewendet.
Modell Einschätzung trifft zu maximieren, die negative freie Energie Schätzungen der Modelle (F) für einen gegebenen Datensatz (Friston et al., 2003). Diese Methode stellt sicher, dass die Model Fit die Parameter auf sparsame Weise verwendet (Ewbank et al., 2011). Die geschätzten Modelle wurden verglichen, basierend auf den Modellbeweisen p(y|m), bei denen es sich um die Wahrscheinlichkeit p handelt, beobachtete Daten y zu erhalten, die von einem bestimmten Modell m angegeben wurden (Friston et al., 2003; Stephan et al., 2009)., In der vorliegenden Studie wenden wir die negative freie Energie-Näherung (variational freie-Energie), um das Protokoll Beweise (MacKay, 2003; Friston et al., 2007). Bayesian Model Selection (BMS) durchgeführt wurde, sowohl den zufälligen (RFX) und Festnetz (FFX) effektdesigns (Stephan et al., 2009). BMS RFX ist resistenter gegen Ausreißer als FFX und geht nicht davon aus, dass dasselbe Modell die Funktion für jeden Teilnehmer erklären würde (Stephan et al., 2009). Mit anderen Worten RFX ist weniger empfindlich gegenüber Rauschen., Im RFX-Ansatz ist die Ausgabe der Analyse die Exceedanzwahrscheinlichkeit des Modellraums, die das Ausmaß ist, in dem ein Modell die gemessenen Daten eher erklärt als andere Modelle. Die andere Ausgabe der RFX-Analyse ist die erwartete posteriore Wahrscheinlichkeit, die die Wahrscheinlichkeit widerspiegelt, dass ein Modell die beobachteten Daten generiert, was unterschiedliche Verteilungen für verschiedene Modelle ermöglicht. Beide Parameterwerte werden durch die Erweiterung des Modellraums (d.h., durch Erhöhen der Anzahl von Modellen) verhalten sie sich daher relativ und Modelle mit gemeinsam genutzten Merkmalen und unplausiblen Modellen können die Ausgabe der Analyse verzerren. Daher haben wir neben dem direkten Vergleich der 28 erstellten Modelle den Modellraum unter Verwendung der Methoden von Penny et al. in Familien mit ähnlichen Konnektivitätsmustern unterteilt. (2010).
Da mehrere frühere DCM-Studien auf die enge bidirektionale Verbindung zwischen FFA und OFA hinweisen (Ishai, 2008; Gschwind et al.,, 2012) in unserer Analyse waren diese beiden Bereiche immer miteinander verbunden und LO war auf jede biologisch plausible Weise mit ihnen verbunden. Die 28 relevanten Modelle wurden anhand struktureller Unterschiede in drei Modellfamilien eingeteilt (Penny et al., 2010; Ewbank et al., 2011). Familie 1 enthält Modelle mit linearen Verbindungen zwischen den drei Bereichen, vorausgesetzt, dass Informationen über die OFA vom LO zum FFA fließen. Familie 2 enthält Modelle mit einer dreieckigen Struktur, bei denen LO Eingaben direkt an die FFA sendet und die OFA auch direkt mit der FFA verknüpft ist., Familie 3 enthält Modelle, in denen die drei Bereiche miteinander verknüpft sind und einen kreisförmigen Informationsfluss voraussetzen (Abbildung 2). Um die Anzahl der Modelle in diesem Schritt der Analyse zu begrenzen, modulierten die Inputs ausschließlich die Aktivität ihrer Eintrittsbereiche. Die drei Familien wurden durch ein zufälliges Design BMS verglichen.
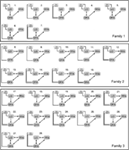
Abbildung 2. Die 28 analysierten Modelle. Schwarze Linien markieren die Aufteilung zwischen den drei Familien mit unterschiedlichen A-Matrixstrukturen. Einzelheiten finden Sie im Abschnitt “ Materialien und Methoden.,“
Zweitens wurden die Modelle aus der Winner-Familie weiter ausgearbeitet, indem jedes plausible Modell mit modulatorischen Verbindungen unter Anwendung von drei Einschränkungen erstellt wurde. Erstens modulieren sowohl Flächen als auch Objekte mindestens eine Inter-Areale-Verbindung. Zweitens wirken sich bei bidirektionalen Verbindungen die modulatorischen Eingänge auf beide Richtungen aus. Drittens, wenn face eine direkte Eingabe in OFA gibt, gehen wir davon aus, dass es immer auch die OFA–FFA-Verbindung moduliert (siehe Tabelle A2 im Anhang). Diese Modelle wurden in einem zweiten family-wise random BMS-Analyse., Schließlich wurden Mitglieder der Winner-Unterfamilie in ein drittes BMS aufgenommen, um ein einzelnes Modell mit der höchsten Überschreitungswahrscheinlichkeit zu finden.
Ergebnisse
Die bayessche Modellauswahl wurde verwendet, um zu entscheiden, welche Modellfamilie die gemessenen Daten am besten erklärt. Wie unsere Ergebnisse zeigen, hat die dritte Familie die anderen beiden übertroffen und eine Exceedanzwahrscheinlichkeit von 0.995 im Vergleich zu 0.00 der ersten Familie und 0.004 der zweiten Familie (Abbildungen 3A,B)., Die Winner-Modellfamilie (Familie 3; Abbildung 2, unten) enthält 12 Modelle, die Verbindungen zwischen LO und FFA, OFA und FFA sowie LO und OFA aufweisen, sich jedoch in der Direktionalität der Verbindungen sowie an der Stelle der Eingabe in das Netzwerk unterscheiden.

Abbildung 3. Ergebnisse von BMS RFX auf der Ebene der Familien. (A) Die erwartete Wahrscheinlichkeiten der Familie-basierten Vergleich dargestellt sind, mit der gemeinsamen überschreitung Wahrscheinlichkeiten (B).,
In einem zweiten Schritt wurden alle möglichen Modulationsmodelle für die 12 Modelle der Familie 3 entworfen (siehe Tabelle A2 im Anhang; Materialien und Methoden für Details). Dies führte zu 122 Modelle, die eingegeben wurden, in der BMS-Familie-wise random Analyse, mit 12 sub-Familien. Wie aus den Abbildungen 4A, B ersichtlich, übertraf die Modellunterfamilie 4 die anderen Unterfamilien mit einer Exceedanzwahrscheinlichkeit von 0,79. Als dritten Schritt wurden die Modelle innerhalb der Gewinner-Unterfamilie 4 in ein Random Effect BMS eingegeben. Abbildung 5 zeigt die 18 getesteten Varianten des Modells 20., Das Modell mit der höchsten Überschreitungswahrscheinlichkeit (p = 0,75) war Modell 4 (siehe Abbildung 6). Dies bedeutet, dass das Siegermodell bidirektionale Verbindungen zwischen allen Bereichen und Gesichts-und Objekteingaben enthält, die überraschenderweise beide in die LO eingehen. Darüber hinaus haben Flächen eine modulatorische Wirkung auf die Verbindung zwischen LO und FFA, während Objekte die Verbindung zwischen LO und OFA modulieren.

Abbildung 4. Ergebnisse von BMS RFX auf der Ebene der Unterfamilien., (A) Die erwartete Wahrscheinlichkeiten der Familie-basierten Vergleich dargestellt sind, mit der gemeinsamen überschreitung Wahrscheinlichkeiten (B).

Abbildung 5. Modelle der Unterfamilie 4. Alle Modelle haben das gleiche DCM.Eine Struktur (identisch mit Modell 20 in Familie 3), DCM.B Struktur unterscheidet sich von Modell zu Modell. Gestrichelte Pfeile symbolisiert Gesicht modulatorischen Effekt, während gepunktete Quadrat-Pfeile Objektmodulation zeigt.
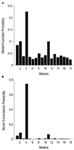
Abbildung 6., Ergebnisse von BMS innerhalb der Unterfamilie 4. (A) Die erwartete Wahrscheinlichkeiten der Familie-basierten Vergleich dargestellt sind, mit der gemeinsamen überschreitung Wahrscheinlichkeiten (B).
Zur Analyse von Parameterschätzungen des Gewinnermodells über die Gruppe der Probanden hinweg wurde eine Zufallseffekt-Approximation verwendet. Alle subjektspezifischen maximalen a posteriori (MAP) Schätzungen wurden in einen t-Test für einzelne Mittel eingegeben und gegen 0 getestet (Stephan et al., 2010; Desseilles et al., 2011). Die mit einem Sternchen indizierten Ergebnisse in Abbildung 7 unterschieden sich signifikant von 0 (p < 0.,05).
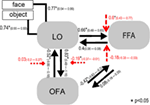
Abbildung 7. Die Struktur des Siegermodells. Einfache Linien kennzeichnen das Objekt und Gesicht Eingabeimpulse an das System (DCM.C). Schwarze Pfeile zeigen interregionale Verbindungen (DCM.A) während die roten Pfeile für die modulatorischen Verbindungen stehen (DCM.B): Die Gesichtsmodulation wird mit gestrichelten Pfeilen bezeichnet, während die Objektmodulation mit gestrichelten Pfeilen mit quadratischem Kopf bezeichnet wird. Es werden Durchschnittswerte auf Gruppenebene von Kartenschätzungen und 95%-Konfidenzintervallen dargestellt., Die Mittelwerte wurden gegen 0 getestet und signifikante Ergebnisse werden mit * if p < 0.05.,
Das Hauptergebnis der vorliegenden effektiven Konnektivitätsstudie legt nahe, dass (a) LO über bidirektionale Verbindungen zu beiden Bereichen direkt mit dem OFA–FFA-Gesichtsverarbeitungssystem verbunden ist; (b) Nicht-Gesichts-und Gesichtseingänge werden auf der Ebene okzipito-temporaler Bereiche vermischt und gelangen über LO in das System.LO und OFA Verbindung deutlich.
Die Rolle von LO in der Objektwahrnehmung ist aus früheren Studien bekannt (Malach et al.,, 1995; Grill-Spector et al., 1998a,b, 2000; Lerner et al., 2001, 2008). Obwohl frühere Studien in der Regel eine erhöhte Aktivität für komplexe Objekte sowie für Gesichter in LO fanden, ist der Bereich normalerweise mit Objekten verbunden, und seiner Rolle bei der Gesichtsverarbeitung wird relativ weniger Bedeutung beigemessen. In der vorliegenden Studie, effektive Konnektivität Analyse aufgestellt, die LO in das zentrale Netz der Gesichts-Wahrnehmung. Die direkte Verbindung zwischen OFA und FFA wurde bisher sowohl funktionell als auch anatomisch nachgewiesen (Gschwind et al., 2012)., Da es jedoch keine aktuellen Daten zur Rolle von LO in diesem System gibt, haben wir es auf verschiedene plausible Weise mit den beiden anderen Regionen verknüpft.
Das erste zufällige BMS zeigte, dass in der Siegermodellfamilie LO sowohl mit FFA als auch mit OFA verbunden ist und die Verbindungen bidirektional sind. Daher wird hervorgehoben, dass LO eine direkte strukturelle Verbindung zu FFA haben kann., Bei der Modellierung aller möglichen modulatorischen Effekte haben wir festgestellt, dass eine Unterfamilie von Modellen gewonnen hat, bei denen sowohl Objekt-als auch Gesichtseingaben über das LO in das System gelangen, wobei angenommen wird, dass das LO eine allgemeine und wichtige Eingabebereichsrolle spielt. Seit früheren funktionalen Konnektivitätsstudien begannen alle mit der Analyse des Face-Processing-Netzwerks auf IOG-Ebene, entsprechend OFA (Fairhall und Ishai, 2007; Ishai, 2008; Cohen Kadosh et al., 2011; Dima et al., 2011; Foley et al., 2012) es ist nicht verwunderlich, dass sie die bedeutende Rolle von LO übersehen haben., Gesichter sind jedoch tatsächlich eine bestimmte Kategorie visueller Objekte, was darauf hindeutet, dass Neuronen, die für Objekte und Formen empfindlich sind, zumindest bis zu einem gewissen Grad auch von Gesichtern aktiviert werden sollten. In der Tat deuten Einzelzellstudien an nichtmenschlichen Primaten darauf hin, dass der inferior-temporale Kortex, der vorgeschlagene Homolog menschlicher Zellen im makaken Gehirn (Denys et al., 2004; Sawamura et al., 2006) hat auch Neuronen, die auf Gesichter reagieren (Perrett et al., 1982, 1985; Desimone et al., 1984; Hasselmo et al., 1989; Young und Yamane, 1992; Sugase et al., 1999)., Die intime Verbindung von LO zu OFA und FFA, die in der vorliegenden Studie vorgeschlagen wurde, könnte die Tatsache unterstreichen, dass Gesichter und Objekte im ventralen Sehweg nicht vollständig getrennt verarbeitet werden, eine Schlussfolgerung, die auch durch neuere funktionelle Bildgebungsdaten gestützt wird (Rossion et al., 2012). Die modulatorische Wirkung der Strebeingabe auf die LO–FFA-Verbindung legt nahe, dass LO eine Rolle bei der Strebverarbeitung spielen muss, die höchstwahrscheinlich mit der früheren strukturellen Verarbeitung von Streben zusammenhängt, eine Aufgabe, die zuvor hauptsächlich OFA übertragen wurde (Rotshtein et al., 2005; Fox et al., 2009)., Schließlich zeigen die Parameter auf Gruppenebene des Siegermodells, dass die Verbindung zwischen LO, OFA und FFA hauptsächlich hierarchisch ist und die Rückkopplungsverbindungen von FFA zu OFA und LO zumindest während der angewandten Fixierungsaufgabe eine schwächere Rolle im System spielen.
Durch die Modellierung der effektiven Konnektivität zwischen strebrelevanten Bereichen und LO schlagen wir vor, dass LO eine bedeutende Rolle bei der Verarbeitung von Flächen spielt.,
Interessenkonflikterklärung
Die Autoren erklären, dass die Untersuchung ohne kommerzielle oder finanzielle Beziehungen durchgeführt wurde, die als potenzieller Interessenkonflikt ausgelegt werden könnten.
Danksagungen
Diese Arbeit wurde von der Deutschen Forschungsgemeinschaft (KO 3918/1-1) und der Universität Regensburg unterstützt. Wir danken Ingo Keck und Michael Schmitgen für die Diskussion.
Campbell, R. (2011). Speechreading und der Bruce-Jungen Modell Gesicht Anerkennung: frühe Ergebnisse und aktuelle Entwicklungen. Br. J. Psychol. 102, 704–710.,
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text
Fairhall, S. L., und Ishai, A. (2007). Effektive Konnektivität innerhalb des verteilten kortikalen Netzwerks für die Gesichtswahrnehmung. Cereb. Cortex 17, 2400-2406.
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text
Hoffman, E. A., und Haxby, J. V. (2000). Unterschiedliche Darstellungen von Augenblick und Identität im verteilten menschlichen neuronalen System für die Gesichtswahrnehmung. Nat. Neurowissenschaften. 3, 80–84.
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text
Kourtzi, Z., und Kanwisher, N. (2001). Darstellung der wahrgenommenen Objektform durch den menschlichen lateralen Okzipitalkomplex. Science 293, 1506-1509.
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text
MacKay, D. J. C. (2003). Informationstheorie Inferenz und Lernalgorithmen. Cambridge: Cambridge University Press.
Nasanen, R. (1999). Räumliche Frequenzbandbreite bei der Erkennung von Gesichtsbildern verwendet. Vision Res. 39, 3824-3833.
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text
Rossion, B., Schiltz, C., und Crommelinck, M., (2003b). Die funktionell definierten rechten okzipitalen und fusiformen „Gesichtsbereiche“ unterscheiden sich von visuell bekannten Gesichtern. Neuroimage 19, 877-883.
CrossRef Full Text
Sawamura, H., Orban, G. A., and Vogels, R. (2006). Die Selektivität der neuronalen Anpassung stimmt nicht mit der Antwortselektivität überein: eine Einzelzellstudie des fMRI-Anpassungsparadigmas. Neuron 49, 307-318.
Pubmed Abstract / Pubmed Volltext / CrossRef Volltext
















Schreibe einen Kommentar