 Quelle auf GitHub anzeigen
Quelle auf GitHub anzeigen Dieses Tutorial zeigt das Training eines einfachen faltungsneuronalen Netzwerks (CNN) zur Klassifizierung von CIFAR-Bildern. Da dieses Tutorial die Keras Sequential API verwendet, dauert das Erstellen und Trainieren unseres Modells nur wenige Codezeilen.,
TensorFlow importieren
import tensorflow as tffrom tensorflow.keras import datasets, layers, modelsimport matplotlib.pyplot as pltHerunterladen und Vorbereiten des CIFAR10-Datensatzes
Der CIFAR10-Datensatz enthält 60.000 Farbbilder in 10 Klassen mit 6.000 Bildern in jeder Klasse. Der Datensatz ist in 50.000 Trainingsbilder und 10.000 Testbilder unterteilt. Die Klassen schließen sich gegenseitig aus, und es gibt keine überlappung zwischen Ihnen.
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz170500096/170498071 - 11s 0us/step
Überprüfen Sie die Daten
Um sicherzustellen, dass der Datensatz korrekt aussieht, zeichnen wir die ersten 25 Bilder aus dem Trainingssatz und zeigen den Klassennamen unter jedem Bild an.,

Erstellen Sie die Faltungsbasis
Die 6 folgenden Codezeilen definieren die Faltungsbasis anhand eines gemeinsamen Musters: eines Stapels von Conv2D-und MaxPooling2D-Ebenen.
Als Eingabe nimmt ein CNN Tensoren der Form (image_height, image_width, color_channels) an und ignoriert die Stapelgröße. Wenn Sie neu in diesen Dimensionen sind, bezieht sich color_channels auf (R, G, B). In diesem Beispiel konfigurieren Sie unseren CNN für die Verarbeitung von Shape-Eingaben (32, 32, 3), dem Format von CIFAR-Bildern. Sie können dies tun, indem Sie das Argument input_shape an unsere erste Ebene übergeben.,
Lassen Sie uns die Architektur unseres bisherigen Modells anzeigen.
model.summary()Oben können Sie sehen, dass die Ausgabe jeder Conv2D und MaxPooling2D Schicht ist ein 3D-tensor der Form (Höhe, Breite, Kanäle). Die Breite und Höhe Abmessungen neigen dazu, zu schrumpfen, wie Sie tiefer im Netzwerk gehen. Die Anzahl der Ausgabekanäle für jede Conv2D-Schicht wird durch das erste Argument (z. B. 32 oder 64) gesteuert. Wenn Breite und Höhe schrumpfen, können Sie es sich normalerweise (rechnerisch) leisten, mehr Ausgabekanäle in jeder Conv2D-Ebene hinzuzufügen.,
Fügen Sie dichte Schichten hinzu
Um unser Modell zu vervollständigen, führen Sie den letzten Ausgabetensor von der Faltungsbasis (der Form (4, 4, 64)) in eine oder mehrere dichte Schichten ein, um eine Klassifizierung durchzuführen. Dichte Schichten nehmen Vektoren als Eingabe (die 1D sind), während der aktuelle Ausgang ein 3D-Tensor ist. Zuerst glätten (oder entrollen) Sie die 3D-Ausgabe auf 1D und fügen dann eine oder mehrere dichte Ebenen hinzu. CIFAR verfügt über 10 Ausgabeklassen, sodass Sie eine letzte dichte Ebene mit 10 Ausgängen verwenden.
model.add(layers.Flatten())model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10))Hier ist die komplette Architektur des Modells.,
model.summary()Wie Sie sehen, wurden unsere (4, 4, 64) Ausgänge in Formvektoren (1024) abgeflacht, bevor Sie zwei dichte Schichten durchliefen.
Kompilieren und trainieren Sie das Modell
Bewerten Sie das Modell
313/313 - 1s - loss: 0.8840 - accuracy: 0.7157
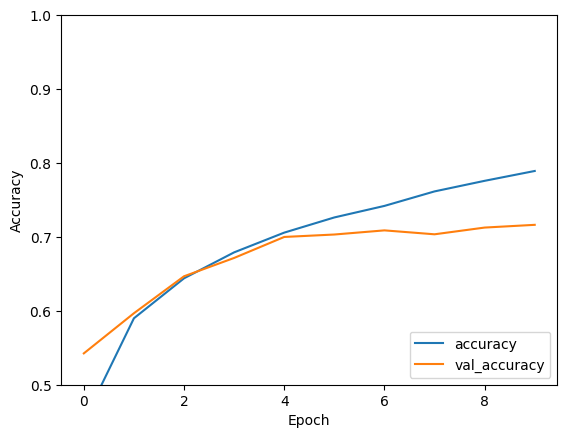
print(test_acc)















Schreibe einen Kommentar