wprowadzenie
neuronowe przetwarzanie twarzy jest szeroko badanym tematem kognitywistyki. Na podstawie badań obrazowania funkcjonalnego, nagrań jednokomórkowych i badań neuropsychologicznych zasugerowano, że przetwarzanie twarzy jest wykonywane przez rozproszoną sieć, obejmującą kilka obszarów korowych mózgu ssaków (Haxby et al., 2000; Marotta et al., 2001; Rossion et al., 2003a; Avidan et al., 2005; Sorger et al., 2007)., Podczas gdy zakres tej sieci przetwarzania twarzy jest obecnie przedmiotem intensywnej debaty (Ishai, 2008; Wiggett and Downing, 2008) większość badaczy zgadza się, że istnieje wiele obszarów korowych aktywowanych przez bodźce twarzy. Najbardziej wpływowy model percepcji twarzy, oparty na oryginalnym modelu Bruce 'a i Younga, 1986; Young and Bruce, 2011) proponuje rozróżnienie między przedstawieniem niezmiennych i wariantowych aspektów percepcji twarzy w stosunkowo niezależny sposób, rozdzielony na” rdzeń „i” rozszerzoną ” część (Haxby et al., 2000)., Najważniejszymi regionami „sieci bazowej” są obszary potylicy i żyłki bocznej (FG). Obszary tych dwóch regionów anatomicznych wydają się być wyspecjalizowane do różnych zadań: podczas gdy potyliczny obszar twarzy (OFA), położony na Dolnym zakręcie potylicznym (IOG) wydaje się być zaangażowany w strukturalne przetwarzanie twarzy, fusiform obszar twarzy (FFA) przetwarza twarze w sposób wyższego poziomu, przyczyniając się na przykład do przetwarzania tożsamości (Sergent et al., 1992; George et al., 1999; Ishai et al., 1999; Hoffman and Haxby, 2000; Rossion et al., 2003a, b; Rotshtein et al.,, 2005). Ponadto zmienne aspekty twarzy (takie jak mimika twarzy, kierunek wzroku, ekspresja, ruchy warg (Perrett et al., 1985, 1990), lub czytanie z ust (Campbell, 2011) wydają się być przetwarzane w superior temporal sulcus (STS; Puce et al., 1998; Hoffman and Haxby, 2000; Winston et al., 2004). Trzy wyżej wymienione obszary (FFA, OFA, STS) tworzą tak zwany „rdzeń” percepcyjnego systemu przetwarzania twarzy (Haxby et al., 2000; Ishai et al., 2005)., Podczas gdy podstawowe informacje o twarzach są przetwarzane przez ten podstawowy system złożone informacje na temat nastroju innych, poziomu zainteresowania, atrakcyjności lub kierunku uwagi również dodaje informacje do percepcji twarzy i jest przetwarzane przez dodatkowy, tak zwany „rozszerzony” system (Haxby et al., 2000). System ten zawiera regiony mózgu z dużą różnorodnością funkcji poznawczych związanych z przetwarzaniem zmiennych aspektów twarzy (Haxby et al., 2000; Ishai et al., 2005) i obejmują obszary takie jak ciało migdałowate, insula, dolny zakręt czołowy, a także korę okołoczołową (Haxby et al.,, 2000, 2002; Fairhall i Ishai, 2007; Ishai, 2008).
interakcje wyżej wymienionych obszarów są modelowane w niniejszym badaniu za pomocą metod obliczania efektywnej łączności między obszarami korowymi. Dynamiczne modelowanie przyczynowe (ang. Dynamic causal modeling, DCM) jest szeroko stosowaną metodą badania efektywnej łączności między regionami mózgu. Jest to ogólne podejście do modelowania wzajemnego wpływu różnych obszarów mózgu na siebie, w oparciu o aktywność fMRI (Friston et al., 2003; Stephan et al., 2010) oraz oszacowanie wzorca wzajemnych połączeń obszarów korowych., DCMs są generatywnymi modelami odpowiedzi neuronalnych, które zapewniają” a posteriori ” szacunki połączeń synaptycznych wśród populacji neuronalnych (Friston et al., 2003, 2007). Istnienie rozproszonej sieci do przetwarzania twarzy zostało po raz pierwszy potwierdzone przez functional connectivity analysis przez Ishai (2008), który twierdził, że centralnym węzłem przetwarzania twarzy jest boczny FG, połączony z obszarami niższego rzędu IOG, a także z STS, ciałem migdałowatym i obszarami czołowymi. Pierwszą próbę ujawnienia sieci przetwarzania twarzy w przypadku realistycznych dynamicznych wyrazów twarzy wykonał Foley et al. (2012)., Potwierdzili rolę obszarów IOG, STS i FG i stwierdzili, że siła połączenia między członkami sieci bazowej (OFA i STS) i rozszerzonego systemu (ciało migdałowate) jest zwiększona dla przetwarzania gestów obciążonych afektem. Obecnie kilka badań opracowało nasze zrozumienie sieci przetwarzania twarzy i ujawniło bezpośredni związek między ciałem migdałowatym i FFA oraz rolę tego połączenia w postrzeganiu przerażających twarzy (Morris et al., 1996; Marco et al., 2006; Herrington et al., 2011)., Wreszcie, wpływ wyższych funkcji poznawczych na percepcję twarzy był również modelowany przez testowanie połączeń kory okołoczołowej z siecią rdzeniową (Li et al., 2010). Znaleziono (Li et al., 2010), że kora okołoczołowa ma wpływ na OFA, co dodatkowo moduluje przetwarzanie informacji FFA.
podczas gdy wcześniejsze skuteczne badania nad łącznością ujawniły szczegóły sieci przetwarzania twarzy związane z różnymi aspektami percepcji twarzy, zignorowano prosty fakt, że twarze mogą być również uważane za obiekty wizualne., Wiemy z dużej grupy eksperymentów, że obiekty wizualne są przetwarzane przez rozproszoną sieć korową, w tym wczesne obszary wizualne, kory potyliczno-skroniowe i brzuszno-skroniowe, w dużej mierze nakładające się na sieć przetwarzania twarzy (Haxby et al., 1999, 2000, 2002; Kourtzi and Kanwisher, 2001; Ishai et al., 2005; Gobbini i Haxby, 2006, 2007; Haxby, 2006; Ishai, 2008). Jednym z głównych obszarów przetwarzania obiektów wizualnych jest boczna kora potyliczna (LOC), którą można podzielić na dwie części: przednio–brzuszną (PF/LOa) i ogonowo–grzbietową (LO; Grill-Spector et al.,, 1999; Halgren et al., 1999). LOC został po raz pierwszy opisany przez Malach et al. (1995), który mierzył zwiększoną aktywność dla obiektów, w tym znanych twarzy, jak również, w porównaniu do zakodowanych obiektów (Malach et al., 1995; Grill-Spector et al., 1998a). Od tego czasu boczna potylica (LO) jest uważana przede wszystkim za obszar selektywny obiektowo, który jednak niezmiennie ma podwyższoną aktywację również dla twarzy (Malach et al., 1995; Puce et al., 1995; Lerner et al., 2001), szczególnie dla odwróconych (Aguirre et al., 1999; Haxby et al., 1999; Epstein et al.,, 2005; Yovel and Kanwisher, 2005).
zaskakujące jest zatem, że podczas gdy kilka badań zajmowało się efektywną łącznością obszarów przetwarzania twarzy, żadne z nich nie uwzględniało roli LO w sieci. W poprzednim badaniu fMRI odkryliśmy, że LO ma kluczową rolę w rywalizacji sensorycznej o bodźce twarzy (Nagy et al., 2011)., Aktywność LO została zmniejszona przez prezentację jednocześnie prezentowanych bodźców współbieżnych i ta redukcja odpowiedzi, która odzwierciedla konkurencję sensoryczną między bodźcami, była większa, gdy otaczający bodziec był twarzą w porównaniu z randomizowanym obrazem szumu w fazie Fouriera. Wynik ten poparł również pomysł, że LO może odgrywać szczególną rolę w postrzeganiu twarzy. Dlatego tutaj zbadaliśmy wyraźnie, przy użyciu metod skutecznej łączności, w jaki sposób LO jest powiązany z FFA i OFA, członkami proponowanej sieci bazowej percepcji twarzy (Haxby et al., 1999, 2000, 2002; Ishai et al., 2005).,
materiały i metody
osoby
w eksperymencie wzięło udział 25 zdrowych uczestników (11 kobiet, mediana: 23 lata, min.: 19 lat, max.: 35 lat). Wszyscy mieli normalne lub skorygowane do normalnego widzenia( self zgłaszane), żaden z nich miał żadnych neurologicznych lub psychologicznych chorób. Uczestnicy dostarczyli pisemną świadomą zgodę zgodnie z protokołami zatwierdzonymi przez Komitet etyczny Uniwersytetu w Ratyzbonie.,
bodźce
obiekty były centralnie prezentowane przez twarze w skali szarości, obiekty bez sensu i randomizowane wersje tych bodźców Fouriera, stworzone przez algorytm (Nasanen, 1999), który zastępuje widmo fazowe przypadkowymi wartościami (od 0° do 360°), pozostawiając widmo amplitudy obrazu nienaruszone, usuwając wszelkie informacje o kształcie. Twarze były pełnymi cyfrowymi obrazami 20 młodych mężczyzn i 20 młodych kobiet. Pasowały one za maską o okrągłym kształcie (średnica 3,5°), eliminując zewnętrzne kontury twarzy(patrz przykładowy obraz na rysunku 1)., Obiekty były bezsensownymi, renderowanymi obiektami (n = 40) o tej samej średniej wielkości co Maska. Luminancja i kontrast (tj. odchylenie standardowe rozkładu luminancji) bodźców zostały zrównane poprzez dopasowanie histogramów luminancji (średnia luminancja: 18 cd/m2) za pomocą programu Photoshop. Bodźce były wyświetlane z powrotem za pomocą projektora wideo LCD (JVC, DLA-G20, Yokohama, Japonia, 72 Hz, rozdzielczość 800 × 600)na półprzezroczystym okrągłym ekranie (ok. 30 ° średnicy), umieszczone wewnątrz otworu skanera w odległości 63 cm od obserwatora., Prezentacja bodźców była kontrolowana za pomocą oprogramowania E-prime (Psychological Software Tools, Pittsburgh, PA, USA). Twarze, obiekty i obrazy szumów Fouriera były prezentowane w kolejnych blokach po 20 s, przeplatanych 20 s okresów pustych (jednolite szare tło o luminancji 18 cd/m2). Bodźce były prezentowane na 300 ms, a następnie ISI 200 ms (2 Hz) w losowej kolejności. Każdy blok był powtarzany pięć razy. Uczestnicy zostali poproszeni o stałą koncentrację na centralnie prezentowanym znaku utrwalenia., Te funkcjonalne biegi lokalizatora były częścią dwóch innych eksperymentów percepcji twarzy, opublikowanych gdzie indziej (Nagy et al., 2009, 2011).

Rysunek 1. Przykładowe bodźce eksperymentu. Wszystkie obrazy były w skali szarości, takie same pod względem rozmiaru, luminancji i kontrastu. Lewy panel pokazuje twarz, cechy charakterystyczne dla płci (takie jak włosy, biżuteria itp.) był ukryty za owalną maską. Środkowy panel pokazuje przykładowy bezsensowny obiekt geometryczny, podczas gdy prawy panel pokazuje randomizowaną wersję obiektów w fazie Fouriera, używaną jako bodźce sterujące.,
pozyskiwanie i analiza danych
obrazowanie wykonano za pomocą skanera 3-T MR Head (Siemens Allegra, Erlangen, Niemcy). Dla serii funkcjonalnej w sposób ciągły pozyskiwaliśmy obrazy (29 plastrów, nachylonych o 10° względem osiowym, Sekwencja EPI ważona T2*, TR = 2000 ms; TE = 30 ms; kąt odwrócenia = 90°; matryce 64 × 64; rozdzielczość w płaszczyźnie: 3 mm × 3 mm; Grubość plastra: 3 mm). Obrazy o wysokiej rozdzielczości ważone T1 uzyskiwano za pomocą sekwencji EPI namagnesowania (MP-RAGE; TR = 2250 ms; TE = 2.,6 ms; 1 mm izotropowy rozmiar voxel) w celu uzyskania skanu strukturalnego 3D (szczegóły patrz Nagy et al., 2011).
funkcjonalne obrazy zostały skorygowane pod kątem opóźnienia akwizycji, wyrównane, znormalizowane do przestrzeni MNI, ponownie próbkowane do rozdzielczości 2 mm × 2 mm × 2 mm i przestrzennie wygładzone za pomocą Jądra Gaussa 8 mm FWHM (SPM8, Welcome Department of Imaging Neuroscience, Londyn, Wielka Brytania; szczegóły analizy danych, patrz Nagy et al., 2011).
wybór VOI
najpierw wybrano wolumeny zainteresowań (VOI), w oparciu o aktywność i ograniczenia anatomiczne (w tym maskowanie odpowiednich regionów mózgu)., Obszary face-selective zostały zdefiniowane jako obszar wykazujący większą aktywację twarzy w porównaniu do obrazów i obiektów Fouriera. FFA został zdefiniowany w bocznym zakręcie Fusiforma, podczas gdy OFA w IOG. LO został zdefiniowany z obiektu > kontrast szumów Fouriera i obrazów twarzy, w obrębie środkowego łuku potylicznego. Wybór VOI opierał się na kontrastach t skorygowanych kontrastem F (p < 0.005 nieskorygowany przy minimalnym rozmiarze klastra wynoszącym 15 voxeli)., Voi były kuliste o promieniu 4 mm wokół aktywacji szczytowej (dla poszczególnych współrzędnych patrz tabela A1 w dodatku). Wariancja wyjaśniona przez pierwszą zmienną wewnętrzną pogrubionych sygnałów wyniosła ponad 79%. W obecnej analizie DCM wykorzystano tylko obszary prawej półkuli, ponieważ kilka badań wskazuje na dominującą rolę tej półkuli w percepcji twarzy (Michel et al., 1989; Sergent et al., 1992).,
efektywna Analiza łączności
efektywna łączność została przetestowana przez DCM-10, zaimplementowana w zestawie narzędzi SPM8 (Wellcome Department of Imaging Neuroscience, Londyn, Wielka Brytania), działającym pod marką Matlab R2008a (The MathWorks, Natick, MA, USA). Modele DCM są definiowane z połączeniami endogennymi, reprezentującymi sprzężenia między regionami mózgu (macierz A), połączeniami modulacyjnymi (macierz B) i wejściami napędowymi (macierz C). Tutaj w macierzy A zdefiniowaliśmy połączenia między regionami face-selective (FFA i OFA) I LO., Obrazy twarzy i obiektów służyły jako wejście napędowe (matryca C) i na tym etapie analizy nie zastosowaliśmy żadnych efektów modulacyjnych na połączenia.
estymacja modelu miała na celu zmaksymalizowanie negatywnych estymacji darmowej energii modeli (F) dla danego zbioru danych (Friston et al., 2003). Metoda ta zapewnia, że model fit wykorzystuje parametry w sposób parsimonious (Ewbank et al., 2011). Oszacowane modele zostały porównane, w oparciu o dowody Modelu p (y / M), które jest prawdopodobieństwem P uzyskania obserwowanych danych y podane przez konkretny model m (Friston et al., 2003; Stephan et al., 2009)., W niniejszym badaniu stosujemy ujemne przybliżenie wolnej energii (wariacyjne swobodne energii) do dowodu log (MacKay, 2003; Friston et al., 2007). Wybór modelu bayesowskiego (BMS) został przeprowadzony zarówno na projektach efektów losowych (RFX), jak i stałych (FFX) (Stephan et al., 2009). BMS RFX jest bardziej odporny na odstające wartości niż FFX i nie zakłada, że ten sam model wyjaśniałby funkcję dla każdego uczestnika (Stephan et al., 2009). Innymi słowy RFX jest mniej wrażliwy na hałas., W podejściu RFX wynikiem analizy jest prawdopodobieństwo przekroczenia przestrzeni modelu, które jest zakresem, w jakim jeden model jest bardziej prawdopodobny do wyjaśnienia mierzonych danych niż inne modele. Innym wynikiem analizy RFX jest oczekiwane prawdopodobieństwo tylne, które odzwierciedla prawdopodobieństwo, że model wygenerował obserwowane dane, umożliwiając różne rozkłady dla różnych modeli. Obie te wartości parametrów są zmniejszone przez poszerzenie przestrzeni modelu (tj.,, zwiększając liczbę modeli), dlatego zachowują się one w sposób względny, a modele o wspólnych cechach i modelach nieprawdopodobnych mogą zniekształcać wynik analizy. Dlatego oprócz bezpośredniego porównania 28 stworzonych modeli podzieliliśmy przestrzeń modelu na rodziny, posiadające podobne wzorce łączności, używając metod Penny et al. (2010).
ponieważ kilka poprzednich badań DCM wskazują na bliskie dwukierunkowe połączenie między FFA i OFA (Ishai, 2008; Gschwind et al.,, 2012) w naszej analizie te dwa obszary były zawsze ze sobą powiązane I LO było z nimi związane w każdy biologicznie wiarygodny sposób. 28 odpowiednich modeli podzielono na trzy rodziny modeli oparte na różnicach strukturalnych (Penny et al., 2010; Ewbank i in., 2011). Rodzina 1 zawiera modele z połączeniami liniowymi między trzema obszarami, zakładając, że informacje przepływają z LO do FFA za pośrednictwem OFA. Rodzina 2 zawiera modele o trójkątnej strukturze, gdzie LO wysyła dane wejściowe bezpośrednio do FFA, a OFA jest również bezpośrednio połączone z FFA., Rodzina 3 zawiera modele, w których trzy obszary są ze sobą powiązane, zakładając kolisty przepływ informacji (Rysunek 2). W celu ograniczenia liczby modeli na tym etapie analizy Dane wejściowe modulowały wyłącznie aktywność swoich obszarów wejściowych. Trzy rodziny zostały porównane przez losowy projekt BMS.
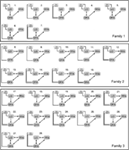
Rysunek 2. 28 analizowanych modeli. Czarne linie wyznaczają podział na trzy rodziny, mające różne struktury macierzy A. Szczegółowe informacje można znaleźć w sekcji ” Materiały i metody.,”
Po Drugie, modele z rodziny winner zostały opracowane dalej, tworząc każdy wiarygodny model z połączeniami modulacyjnymi, stosując trzy ograniczenia. Po pierwsze, zarówno twarze, jak i Obiekty modulują co najmniej jedno połączenie między obszarami. Po drugie, w przypadku połączeń dwukierunkowych wejścia modulacyjne mają wpływ na obie strony. Po trzecie, jeśli face daje bezpośrednie wejście do OFA, to zakładamy, że zawsze moduluje również połączenie OFA-FFA (patrz tabela A2 w dodatku). Modele te zostały wprowadzone do drugiej rodziny analizy losowej BMS., Ostatecznie członkowie ZWYCIĘSKIEJ podrodziny zostali wpisani do trzeciego BMS, aby znaleźć jeden model o największym prawdopodobieństwie przekroczenia.
wyniki
wybór modelu bayesowskiego został użyty do określenia, która rodzina modeli najlepiej wyjaśnia zmierzone dane. Jak pokazują nasze wyniki, trzecia rodzina wykonała pozostałe dwie, z prawdopodobieństwem przekroczenia 0,995 w porównaniu do pierwszej rodziny 0,00 i drugiej rodziny 0,004(rysunki 3A, B)., Rodzina modeli winner (Rodzina 3; Rysunek 2, dół) zawiera 12 modeli, posiadających połączenia między LO i FFA, OFA i FFA oraz LO i OFA, ale różniących się kierunkowością połączeń, jak również miejscem wejścia do sieci.

Rysunek 3. Wyniki BMS RFX na poziomie rodzin. A) przedstawiono oczekiwane prawdopodobieństwa porównań opartych na rodzinie z prawdopodobieństwem wspólnego przekroczenia (B).,
w drugim etapie wszystkie możliwe modele modulacyjne zostały zaprojektowane dla 12 modeli z rodziny 3 (zob. tabela A2 w załączniku; materiały i metody szczegółowe). Doprowadziło to do powstania 122 modeli, które zostały wprowadzone do analizy losowej rodziny BMS, wykorzystując 12 podrodzin. Jak widać na rysunkach 4A, B, Podrodzina model 4 wyprzedziła Pozostałe podrodziny z prawdopodobieństwem przekroczenia 0,79. W trzecim etapie modele w obrębie ZWYCIĘSKIEJ podrodziny 4 zostały wprowadzone w efekt losowy. Rysunek 5 przedstawia 18 przetestowanych odmian modelu 20., Model o największym prawdopodobieństwie przekroczenia (p = 0,75) był modelem 4 (patrz rysunek 6). Oznacza to, że model winner zawiera dwukierunkowe połączenia między wszystkimi obszarami i wejściami twarzy i obiektu, co zaskakujące, oba wchodzą do LO. Ponadto twarze mają modulujący wpływ na połączenie między LO i FFA, podczas gdy obiekty modulują połączenie między LO i OFA.

Rysunek 4. Wyniki BMS RFX na poziomie podrodzin., A) przedstawiono oczekiwane prawdopodobieństwa porównań opartych na rodzinie z prawdopodobieństwem wspólnego przekroczenia (B).

Rysunek 5. Podrodzina 4. Wszystkie modele mają ten sam DCM.Konstrukcja (identyczna z modelem 20 w rodzinie 3), DCM.Struktura B różni się w zależności od modelu. Przerywane strzałki symbolizują efekt modulacji twarzy, podczas gdy kropkowane kwadratowe strzałki pokazują modulację obiektu.
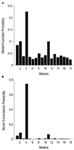
Rysunek 6., Wyniki BMS w obrębie podrodziny 4. A) przedstawiono oczekiwane prawdopodobieństwa porównań opartych na rodzinie z prawdopodobieństwem wspólnego przekroczenia (B).
do analizy estymacji parametrów modelu zwycięzcy w całej grupie badanych wykorzystano losowe przybliżenie efektu. Wszystkie specyficzne dla danego obiektu maksimum a posteriori (MAP) szacunki zostały wprowadzone do testu t dla pojedynczych środków i przetestowane przeciwko 0 (Stephan et al., 2010; Desseilles et al., 2011). Wyniki zindeksowane gwiazdką na rysunku 7 różniły się znacząco od 0 (p < 0.,05).
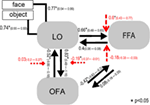
Rysunek 7. Struktura modelu zwycięzcy. Proste linie oznaczają obiekt i twarz bodźce wejściowe do systemu (DCM.C). Czarne strzałki pokazują połączenia międzyregionalne (DCM.A) natomiast czerwone strzałki oznaczają połączenia modulacyjne (DCM.B): modulacja twarzy jest oznaczona strzałkami przerywanymi, podczas gdy modulacja obiektu jest oznaczona strzałkami przerywanymi z kwadratową głową. Na poziomie grupy przedstawiono średnie szacunki MAP I 95% przedziały ufności., Średnie były testowane pod kątem 0, a znaczące wyniki oznaczane są znakiem * if p < 0.05.,
dyskusja
główne wyniki obecnego efektywnego badania łączności sugerują, że A) LO jest podłączone bezpośrednio do systemu przetwarzania twarzy OFA–FFA poprzez dwukierunkowe połączenia do obu obszarów; b) wejścia bez twarzy i twarzy są mieszane na poziomie obszarów potyliczno-skroniowych i wchodzą do systemu przez LO; c) wejście twarzy ma modulujący wpływ na połączenie LO i FFA, podczas gdy object input znacząco moduluje połączenie Lo i OFA.
rola LO w percepcji obiektów jest dobrze znana z poprzednich badań (Malach et al.,, 1995; Grill-Spector et al., 1998a, b, 2000; Lerner et al., 2001, 2008). Jednak pomimo wcześniejszych badań stwierdzono Zwykle zwiększoną aktywność dla obiektów złożonych, a także dla twarzy w LO, obszar ten jest zwykle związany z obiektami i stosunkowo mniejsze znaczenie przypisuje się jego roli w obróbce twarzy. W niniejszym badaniu efektywna analiza połączeń umiejscowiła LO w sieci bazowej percepcji twarzy. Bezpośredni związek między OFA i FFA zostało udowodnione wcześniej zarówno funkcjonalnie i anatomicznie (Gschwind et al., 2012)., Ponieważ jednak nie ma aktualnych danych dotyczących roli LO w tym systemie, połączyliśmy go z pozostałymi dwoma regionami na kilka wiarygodnych sposobów.
pierwszy losowy BMS pokazał, że w rodzinie modeli winner Lo jest połączone zarówno z FFA, jak i OFA, a połączenia są dwukierunkowe. W związku z tym podkreśla, że LO może mieć bezpośrednie strukturalne połączenie z FFA., Dzięki modelowaniu wszystkich możliwych efektów modulacyjnych odkryliśmy, że wygrała Podrodzina modeli, w której zarówno wejścia obiektowe, jak i twarzowe wchodzą do systemu za pośrednictwem LO, zakładając, że LO odgrywa ogólną i ważną rolę regionu wejściowego. Od poprzednich badań łączności funkcjonalnej wszystkie rozpoczęły analizę sieci przetwarzania twarzy na poziomie IOG, odpowiadającej OFA (Fairhall and Ishai, 2007; Ishai, 2008; Cohen Kadosh et al., 2011; Dima i in., 2011; Foley et al., 2012) nie dziwi fakt, że przeoczyli znaczącą rolę LO., Jednak twarze są w rzeczywistości odrębną kategorią obiektów wizualnych, co sugeruje, że neurony wrażliwe na przedmioty i kształty powinny być aktywowane, przynajmniej w pewnym stopniu, również przez twarze. Rzeczywiście, jednokomórkowe badania nie-ludzkich naczelnych sugerują, że kora podrzędna skroniowa, proponowany homolog ludzkiego LO w mózgu makaka (Denys et al., 2004; Sawamura et al., 2006) ma neurony reagujące na twarze, jak również (Perrett et al., 1982, 1985; Desimone et al., 1984; Hasselmo et al., 1989; Young and Yamane, 1992; Sugase et al., 1999)., Intymne połączenie LO z OFA i FFA, sugerowane przez obecne badanie może podkreślić fakt, że twarze i Obiekty nie są przetwarzane całkowicie oddzielnie w brzusznej ścieżce wzrokowej, wniosek poparty przez Najnowsze dane obrazowania funkcjonalnego, jak również (Rossion et al., 2012). Modulacyjny efekt wejścia twarzy na połączeniu LO–FFA sugeruje, że LO musi odgrywać rolę w przetwarzaniu twarzy, najprawdopodobniej związane z wcześniejszym, strukturalnym przetwarzaniem twarzy, zadanie wcześniej złożone głównie do OFA (Rotshtein et al., 2005; Fox et al., 2009)., Wreszcie, parametry na poziomie grupy modelu winner pokazują, że związek między LO, OFA i FFA są głównie hierarchiczne, a połączenia zwrotne z FFA w kierunku OFA I LO odgrywają słabszą rolę w systemie, przynajmniej podczas zastosowanego zadania utrwalania.
podsumowując, modelując efektywną łączność między obszarami istotnymi dla twarzy a LO sugerujemy, że LO odgrywa znaczącą rolę w przetwarzaniu twarzy.,
Oświadczenie o konflikcie interesów
autorzy oświadczają, że badanie zostało przeprowadzone w przypadku braku jakichkolwiek relacji handlowych lub finansowych, które mogłyby być interpretowane jako potencjalny konflikt interesów.
praca ta była wspierana przez Deutsche Forschungsgemeinschaft (KO 3918/1-1) i Uniwersytet w Ratyzbonie. Chcielibyśmy podziękować Ingo Keck i Michael Schmitgen za dyskusję.
Speechreading and The Bruce-Young model of face recognition: early findings and recent developments. Br. J. Psychol. 102, 704–710.,
PubMed Abstract / PubMed Full Text/CrossRef Full Text
Fairhall, S. L., and Ishai, A. (2007). Efektywna łączność w rozproszonej sieci korowej dla percepcji twarzy. Cereb. Cortex 17, 2400-2406.
PubMed Abstract / PubMed Full Text/CrossRef Full Text
Hoffman, E. A., and Haxby, J. V. (2000). Różne reprezentacje spojrzenia oczu i tożsamości w rozproszonym ludzkim systemie nerwowym dla percepcji twarzy. Nat. Neurosci. 3, 80–84.
PubMed Abstract / PubMed Full Text/CrossRef Full Text
Kourtzi, Z., i Kanwisher, N. (2001). Przedstawienie postrzeganego kształtu obiektu przez ludzki boczny kompleks potyliczny. Nauka 293, 1506-1509.
PubMed Abstract / PubMed Full Text/CrossRef Full Text
Teoria informacji, wnioskowanie i algorytmy uczenia się. Cambridge: Cambridge University Press.
Nasanen, R. (1999). Przestrzenne pasmo częstotliwości wykorzystywane do rozpoznawania obrazów twarzy. Vision Res. 39, 3824-3833.
PubMed Abstract / PubMed Full Text/CrossRef Full Text
Rossion, B., Schiltz, C., and Crommelinck, M., (2003b). Funkcjonalnie zdefiniowane prawe obszary potyliczne i fusiform „obszary twarzy” odróżniają powieść od wizualnie znanych twarzy. Neuroimage 19, 877-883.
Pełny tekst
Sawamura, H., Orban, G. A., and Vogels, R. (2006). Selectivity of neuronal adaptation does not match response selectivity: a single-cell study of the fMRI adaptation paradygmat. Neuron 49, 307-318
PubMed Abstract | PubMed Full Text | CrossRef Full Text
















Dodaj komentarz