![]()


![]()



![]()
Amundsen est une découverte de données et de métadonnées moteur pour l’amélioration de la productivité des analystes de données, les données scientifiques et les ingénieurs lors de l’interaction avec les données. Il le fait aujourd’hui en indexant des ressources de données (tableaux, tableaux de bord, Flux, etc.) et alimenter une recherche de style page-rank basée sur les modèles d’utilisation (par exemple, les tables fortement interrogées apparaissent plus tôt que les tables moins interrogées). Pensez – y comme Google Recherche de données. Le projet porte le nom de L’explorateur norvégien Roald Amundsen, la première personne à découvrir le pôle Sud.

Amundsen est hébergé par la LF AI & Fondation de Données. Il comprend trois microservices, une bibliothèque d’ingestion de données et une bibliothèque commune.
- amundsenfrontendlibrary: service Frontend qui est une application Flask avec un frontend React.,

- amundsensearchlibrary: le service de recherche, qui exploite Elasticsearch pour les capacités de recherche, est utilisé pour alimenter la recherche de métadonnées frontend.

- amundsenmetadatalibrary: service de métadonnées, qui exploite Neo4j ou Apache Atlas comme couche persistante, pour fournir diverses métadonnées.

- amundsendatabuilder: bibliothèque d’ingestion de données pour construire un graphique de métadonnées et un index de recherche. Les utilisateurs peuvent charger les données avec un script python avec la bibliothèque ou avec un DAG Airflow important la bibliothèque.,

- amundsencommon: la bibliothèque commune D’Amundsen contient des codes communs parmi les microservices dans Amundsen.

- amundsengremlin: la bibliothèque Amundsen Gremlin contient le code utilisé pour convertir les objets modèle en sommets et arêtes dans gremlin. Il est utilisé pour charger des données dans un backend AWS Neptune.

- amundsenrds: Amundsenrds contient des modèles ORM pour prendre en charge la base de données relationnelle en tant que magasin backend de métadonnées dans Amundsen. Le schéma dans les modèles ORM suit la logique des modèles databuilder., Amundsenrds sera utilisé dans databuilder et metadatalibrary pour le stockage et la récupération de métadonnées avec des bases de données relationnelles.

page d’Accueil¶
- Python = 3.6 ou 3.7
- Node = v10 ou v12 (v14 peut avoir des problèmes de compatibilité)
- npm >= 6
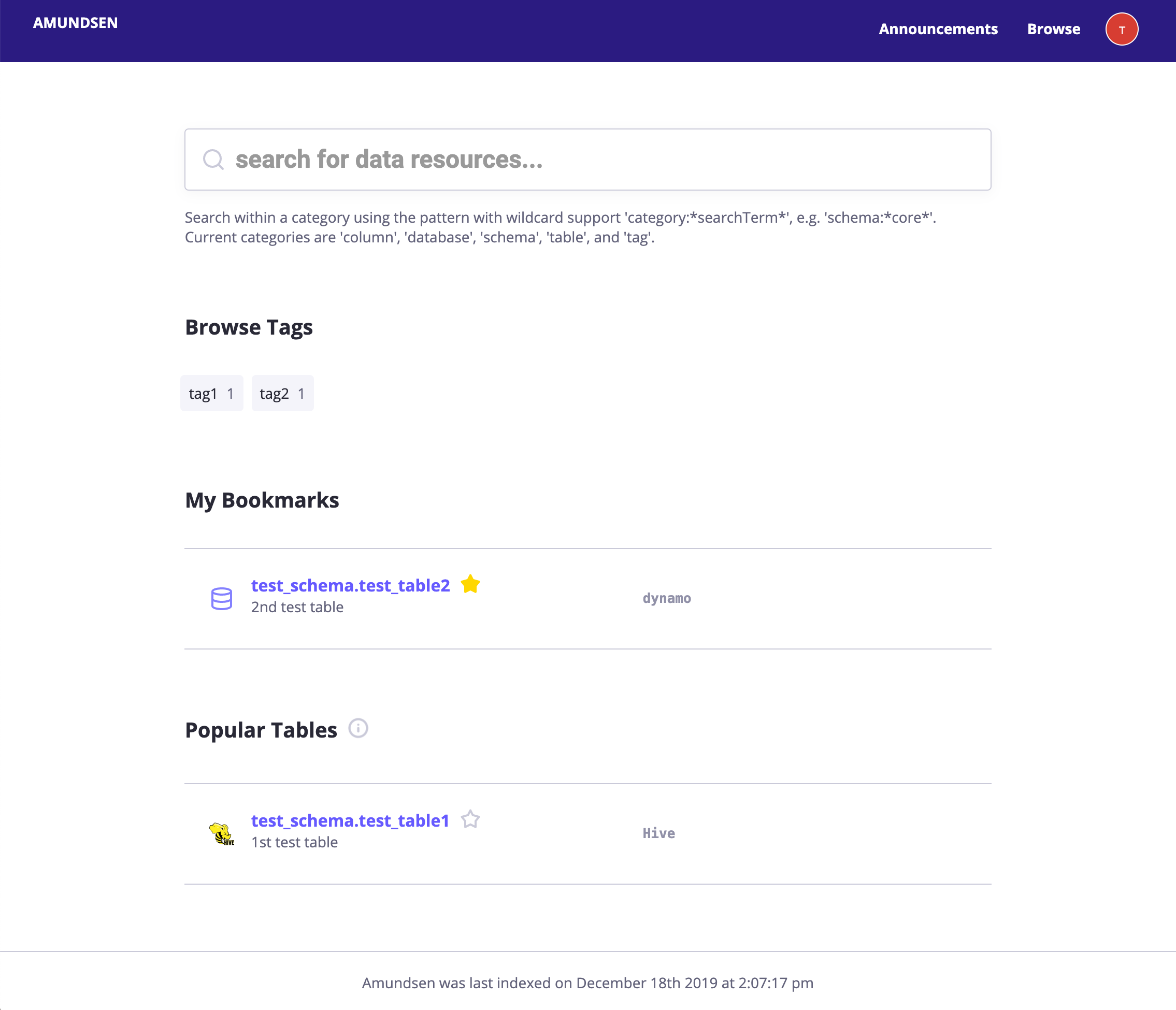
- page de destination: la page de destination pour Amundsen comprenant 1. barres de recherche; 2., tableaux utilisés populaires;
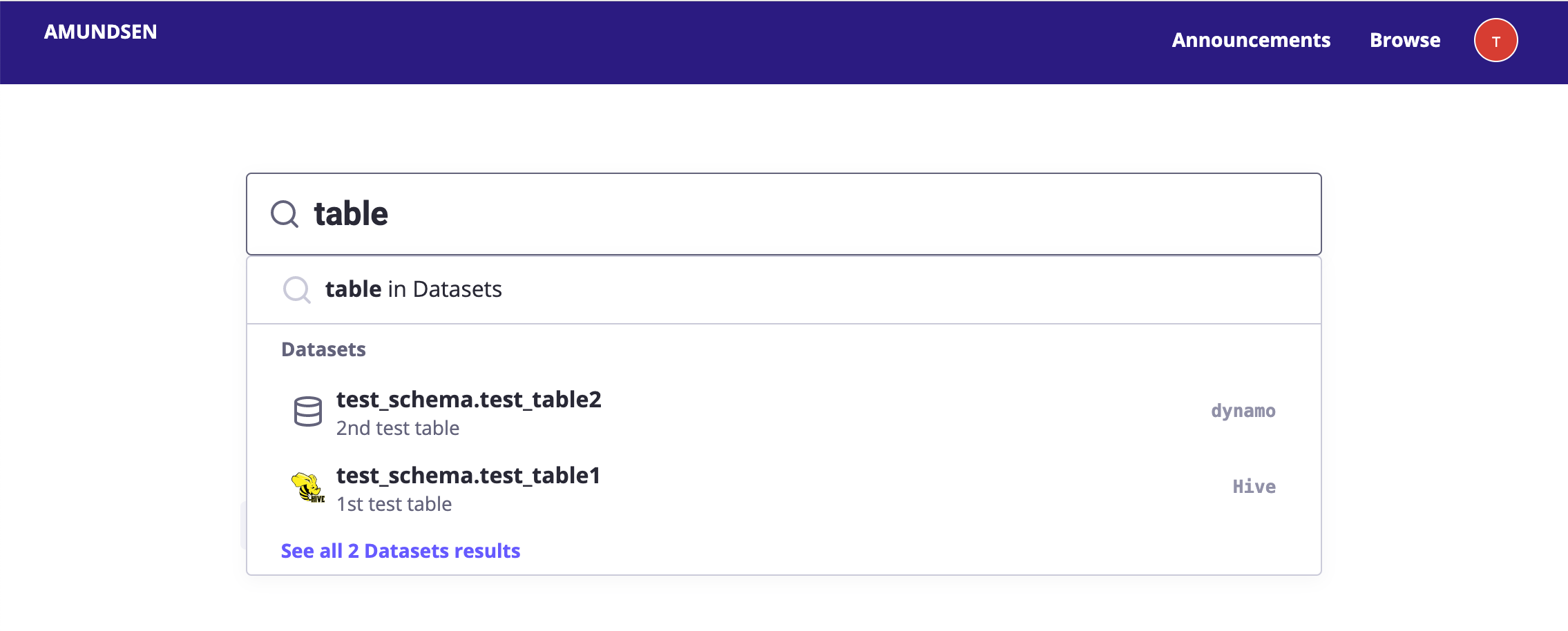
- aperçu de la Recherche: voir les résultats de recherche en ligne lorsque vous tapez
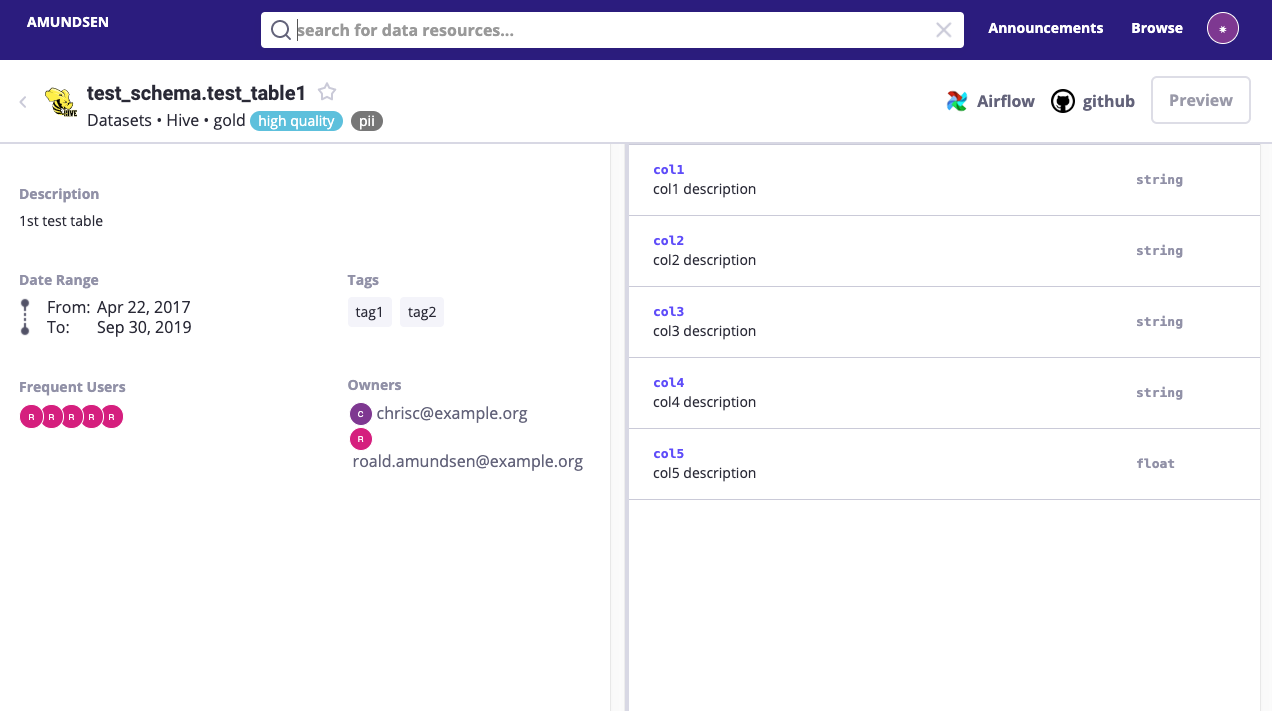
- page de détail de la Table: visualisation D’une table Hive / Redshift
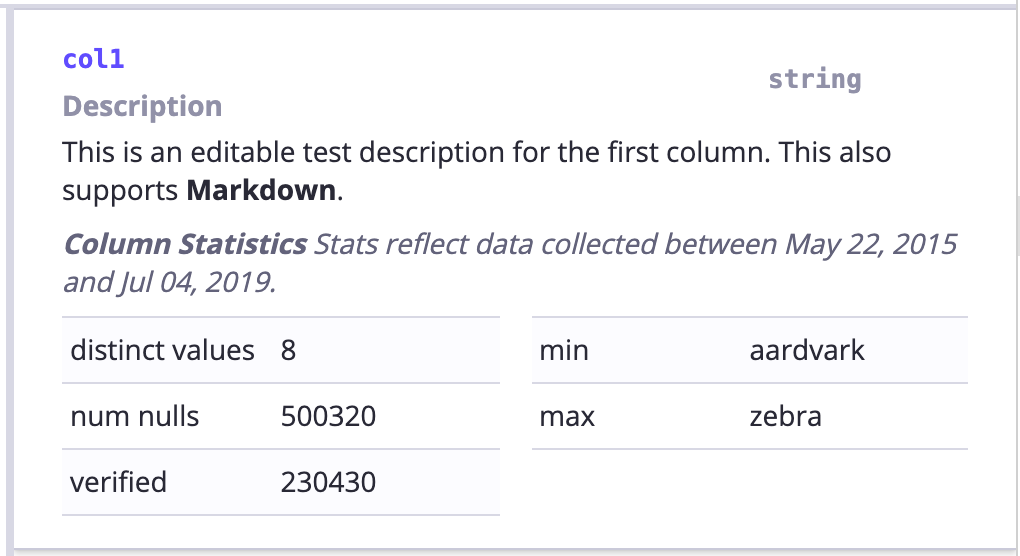
- détail des colonnes: visualisation des colonnes d’une table Hive / Redshift qui comprend un affichage de statistiques optionnel
- page d’aperçu des données: visualisation de L’aperçu des données de la Table qui pourrait s’intégrer avec Apache Superset ou,
- Tables (à partir de bases de données)
- personnes (à partir de systèmes RH)
- tableaux de bord
- Amazon Athena
- Amazon Glue et tout ce qui est construit dessus (comme Databricks Delta – qui est un travail en cours).,
- Amazon Redshift
- Apache Cassandra
- Apache Druid
- Apache Hive
- CSV
- Delta Lake
- Google BigQuery
- IBM DB2
- Microsoft SQL Server
- MySQL
- Oracle (via dbapi ou sql_alchemy)
- PostgreSQL
- soon
- Vertica
- Snowflake
- Mode Analytics
- Redash
- Tableau
- Apache circulation de l’Air
- Apache sur-ensemble
- Amundsen – découverte de données de Lyft& moteur de métadonnées (avril 2019)
- podcast quotidien D’ingénierie logicielle sur Amundsen (avril 2019)
- Comment Lyft conduit la découverte de données (juillet 2019)
- Podcast D’ingénierie de données 2019)
- open sourcing Amundsen: une plate-forme de découverte de données et de métadonnées (oct 2019)
- ajout de la qualité des données dans Amundsen avec des descriptions programmatiques par Sam Shuster d’Edmunds.,Paysage
- Lyft’s Amundsen: Data-Discovery with Built-In Trust
- Comment trouver et organiser vos données à partir de la ligne de commande
- Data Discovery Platform at Bagelcode
- outils de catalogage pour les équipes de données
- Un aperçu des plates-formes de découverte de données et des Solutions Open Source
- Hacking Data Discovery plate-forme
- Bang & Olufsen
- Brex
- Petit
- Cimpress de la Technologie
- Coles Groupe
- Convoi
- Date de Sprints
- Dcard
- Consacré à la Santé
- DHI Groupe
- Edmunds
- Everfi
- Goût
- Hurb
- ING
- Instacart
- iRobot
- Flash
- LMC
- Loft
- Lyft
- Merlin
- PicPay
- Plarium Krasnodar
- PUBG
- Rapide
- REA Groupe
- Remitly
- Place
- WeTransfer
- Journée de travail
Documentation¶
Exigences¶
Interface Utilisateur¶
Veuillez noter que la fantaisie des images ne servent de démonstration.
s’Impliquer dans la Communauté¶
Voulez de l’aide ou voulez-vous aider?Utilisez le bouton de notre en-tête pour rejoindre notre chaîne slack. Les Contributions sont également plus que bienvenues! Comme expliqué dans CONTRIBUTING.md il existe de nombreuses façons de contribuer, tout ne doit pas nécessairement être du code avec de nouvelles fonctionnalités et des corrections de bugs, ainsi que de la documentation, comme des entrées de FAQ, des rapports de bogues, des articles de blog partageant des expériences, etc. tous aident à faire avancer Amundsen. Si vous trouvez une faille de sécurité, veuillez suivre ce guide.,
mise en route¶
veuillez consulter la documentation D’installation D’Amundsen pour un démarrage rapide d’une version par défaut d’Amundsen avec des données factices.
vue D’ensemble de L’Architecture¶
veuillez visiter Architecture pour la vue d’ensemble de L’architecture Amundsen.
entités supportées¶
intégrations supportées¶
connecteurs de Table¶
Amundsen peut également se connecter à n’importe quelle base de données qui fournit une interface dbapi ou sql_alchemy (que la plupart des DBS fournissent).,
tableau de bord Connecteurs¶
ETL Orchestration¶
BI Viz Outil¶
Installation¶
s’il vous Plaît visitez Installation de la ligne directrice sur la façon d’installer Amundsen.
feuille de route¶
veuillez visiter feuille de route Si vous êtes intéressé par les éléments à venir de la feuille de route D’Amundsen.,
Articles de Blog et Interviews¶
réunions communautaires¶
Les réunions communautaires ont lieu le premier jeudi de chaque mois à 9 heures du Pacifique, midi de l’est, 18 heures, heure d’Europe centrale., Lien pour rejoindre
prochaines réunions& notes¶
Vous pouvez la date exacte de la prochaine réunion et l’ordre du jour quelques semaines avant la réunion dans ce document.
Les Notes de toutes les réunions passées sont disponibles ici.
Qui utilise Amundsen?¶
Voici la liste des organisations qui utilisent Amundsen aujourd’hui. Si votre organisation utilise Amundsen, veuillez déposer un PR et mettre à jour cette liste.,Bagelcode
Apache 2.,0 licence.
















Laisser un commentaire