Introduzione
L’elaborazione neurale dei volti è un argomento ampiamente ricercato della scienza cognitiva. Sulla base di studi di imaging funzionale, registrazioni unicellulari e ricerche neuropsicologiche è stato suggerito che l’elaborazione del viso viene eseguita da una rete distribuita, che coinvolge diverse aree corticali del cervello dei mammiferi (Haxby et al., 2000; Marotta et al., 2001; Rossion et al., 2003a; Avidan et al., 2005; Sorger et al., 2007)., Mentre l’estensione di questa rete di elaborazione del viso è attualmente oggetto di un intenso dibattito (Ishai, 2008; Wiggett e Downing, 2008) la maggior parte dei ricercatori concorda sul fatto che ci sono numerose aree corticali attivate da stimoli facciali. Il modello più influente della percezione del viso, basato sul modello originale di Bruce and Young, 1986; Young and Bruce, 2011) propone una distinzione tra la rappresentazione degli aspetti invarianti e varianti della percezione del viso in modo relativamente indipendente, separati in un” nucleo “e una parte” estesa” (Haxby et al., 2000)., Le regioni più importanti della “rete principale” sono le aree del giroscopio fusiforme occipitale e laterale (FG). Le aree di queste due regioni anatomiche sembrano essere specializzate per compiti distinti: mentre l’area della faccia occipitale (OFA), situata sul giro occipitale inferiore (IOG) sembra essere coinvolta nell’elaborazione strutturale delle facce, l’area della faccia fusiforme (FFA) elabora le facce in modo più alto, contribuendo ad esempio all’elaborazione dell’identità (Sergent et al., 1992; George et al., 1999; Ishai et al., 1999; Hoffman e Haxby, 2000; Rossion et al., 2003a, b; Rotshtein et al.,, 2005). Inoltre, gli aspetti mutevoli dei volti (come le espressioni facciali, la direzione dello sguardo, l’espressione, i movimenti delle labbra (Perrett et al., 1985, 1990), o lip-reading (Campbell, 2011) sembrano essere elaborati nel solco temporale superiore (STS; Puce et al. Nel 1998, Hoffman e Haxby, 2000; Winston et al., 2004). Le tre aree sopra menzionate (FFA, OFA, STS) costituiscono il cosiddetto “nucleo” del sistema percettivo di face-processing (Haxby et al., 2000; Ishai et al., 2005)., Mentre le informazioni di base sui volti vengono elaborate da questo sistema principale le informazioni complesse sull’umore, il livello di interesse, l’attrattività o la direzione dell’attenzione degli altri aggiungono anche informazioni alla percezione del viso e vengono elaborate da un ulteriore sistema cosiddetto “esteso” (Haxby et al., 2000). Questo sistema contiene regioni cerebrali con una grande varietà di funzioni cognitive legate all’elaborazione di aspetti facciali mutevoli (Haxby et al., 2000; Ishai et al., 2005) e comprendono aree come l’amigdala, l’insula, il giro frontale inferiore e la corteccia orbitofrontale (Haxby et al.,, 2000, 2002; Fairhall e Ishai, 2007; Ishai, 2008).
Le interazioni delle aree sopra menzionate sono modellate nel presente studio utilizzando metodi che calcolano l’effettiva connettività tra le aree corticali. Dynamic Causal modeling (DCM) è un metodo ampiamente utilizzato per esplorare la connettività efficace tra le regioni del cervello. È un approccio generico per modellare l’influenza reciproca di diverse aree cerebrali l’una sull’altra, basato sull’attività fMRI (Friston et al., 2003; Stephan et al., 2010) e per stimare il modello di interconnessione delle aree corticali., I DCM sono modelli generativi di risposte neurali, che forniscono stime “a posteriori” delle connessioni sinaptiche tra popolazioni neuronali (Friston et al., 2003, 2007). L’esistenza della rete distribuita per l’elaborazione del viso è stata confermata per la prima volta dall’analisi della connettività funzionale di Ishai (2008), che ha affermato che il nodo centrale dell’elaborazione del viso è l’FG laterale, collegato alle aree di ordine inferiore dell’IOG nonché a STS, amigdala e aree frontali. Il primo tentativo di rivelare la rete di elaborazione del viso in caso di espressioni facciali dinamiche realistiche è stato fatto da Foley et al. (2012)., Hanno confermato il ruolo delle aree IOG, STS e FG e hanno scoperto che la forza di connessione tra i membri della rete principale (OFA e STS) e del sistema esteso (amigdala) è aumentata per l’elaborazione di gesti carichi di effetti. Attualmente, diversi studi hanno elaborato la nostra comprensione sulla rete di elaborazione del volto e hanno rivelato un legame diretto tra amigdala e FFA e il ruolo di questa connessione nella percezione dei volti timorosi (Morris et al., 1996; Marco et al., 2006; Herrington et al., 2011)., Infine, l’effetto delle funzioni cognitive superiori sulla percezione del viso è stato anche modellato testando le connessioni della corteccia orbitofrontale alla rete principale (Li et al., 2010). È stato trovato (Li et al., 2010) che la corteccia orbitofrontale ha un effetto sull’OFA, che modula ulteriormente l’elaborazione delle informazioni dell’FFA.
Mentre precedenti studi di connettività efficaci hanno rivelato i dettagli della rete di elaborazione del viso relativi a vari aspetti della percezione del viso, hanno ignorato il semplice fatto che i volti possono anche essere considerati come oggetti visivi., Sappiamo da un ampio corpo di esperimenti che gli oggetti visivi sono elaborati da una rete corticale distribuita, comprese le prime aree visive, le cortecce occipito-temporali e ventrale–temporali, in gran parte sovrapposte alla rete di elaborazione del viso (Haxby et al., 1999, 2000, 2002; Kourtzi e Kanwisher, 2001; Ishai et al., 2005; Gobbini e Haxby, 2006, 2007; Haxby, 2006; Ishai, 2008). Una delle principali aree di elaborazione degli oggetti visivi è la corteccia occipitale laterale (LOC), che può essere divisa in due parti: la parte anteriore–ventrale (PF/LOa) e la parte caudale–dorsale (LO; Grill-Spector et al.,, 1999; Halgren et al., 1999). Il LOC è stato descritto per la prima volta da Malach et al. (1995), che ha misurato una maggiore attività per oggetti, inclusi anche volti famosi, rispetto agli oggetti strapazzati (Malach et al., 1995; Grill-Spector et al., 1998a). Da allora, l’occipitale laterale (LO) è considerato principalmente come un’area oggetto-selettiva, che tuttavia invariabilmente si trova ad avere un’attivazione elevata anche per le facce (Malach et al., 1995; Puce et al., 1995; Lerner et al., 2001), specialmente per quelli invertiti (Aguirre et al., 1999; Haxby et al., 1999; Epstein et al.,, 2005; Yovel e Kanwisher, 2005).
Quindi, è piuttosto sorprendente che mentre diversi studi si sono occupati dell’effettiva connettività delle aree di face-processing, nessuno di loro ha considerato il ruolo della LO nella rete. In un precedente studio fMRI abbiamo scoperto che LO ha un ruolo cruciale nella competizione sensoriale per gli stimoli facciali (Nagy et al., 2011)., L’attività di LO è stata ridotta dalla presentazione di stimoli simultanei presentati simultaneamente e questa riduzione della risposta, che riflette la competizione sensoriale tra stimoli, era più grande quando lo stimolo circostante era un volto rispetto a un’immagine di rumore randomizzata in fase di Fourier. Questo risultato ha anche supportato l’idea che LO possa svolgere un ruolo specifico nella percezione del viso. Pertanto, qui abbiamo esplorato esplicitamente, utilizzando metodi di connettività efficace, come LO è collegato a FFA e OFA, membri della rete principale proposta di percezione del volto (Haxby et al., 1999, 2000, 2002; Ishai et al., 2005).,
Materiali e metodi
Soggetti
Venticinque partecipanti sani hanno preso parte all’esperimento (11 femmine, mediana: 23 anni, min.: 19 anni, max.: 35 anni). Tutti avevano una visione normale o corretta (auto riportata), nessuno di loro aveva malattie neurologiche o psicologiche. I soggetti hanno fornito il loro consenso informato scritto in conformità con i protocolli approvati dal Comitato Etico dell’Università di Ratisbona.,
Stimoli
I soggetti sono stati presentati centralmente da facce in scala di grigi, oggetti non sense e le versioni randomizzate di Fourier di questi stimoli, create da un algoritmo (Nasanen, 1999) che sostituisce lo spettro di fase con valori casuali (che vanno da 0° a 360°), lasciando intatto lo spettro di ampiezza dell’immagine, rimuovendo I volti erano immagini digitali full-front di 20 giovani maschi e 20 giovani femmine. Erano in forma dietro una maschera di forma rotonda (3,5 ° di diametro) eliminando i contorni esterni delle facce (vedere un’immagine di esempio in Figura 1)., Gli oggetti erano oggetti non sense, renderizzati (n = 40) aventi la stessa dimensione media della maschera facciale. La luminanza e il contrasto (cioè la deviazione standard della distribuzione di luminanza) degli stimoli sono stati equiparati facendo corrispondere gli istogrammi di luminanza (luminanza media: 18 cd/m2) usando Photoshop. Gli stimoli sono stati proiettati indietro tramite un videoproiettore LCD (JVC, DLA-G20, Yokohama, Giappone, 72 Hz, risoluzione 800 × 600) su uno schermo circolare traslucido (app. diametro 30°), posto all’interno del foro dello scanner a 63 cm dall’osservatore., La presentazione dello stimolo è stata controllata tramite software E-prime (Strumenti software psicologici, Pittsburgh, PA, USA). Volti, oggetti e immagini di rumore di Fourier sono stati presentati in blocchi successivi di 20 s, intercalati con 20 s di periodi vuoti (sfondo grigio uniforme con una luminanza di 18 cd/m2). Gli stimoli sono stati presentati per 300 ms e sono stati seguiti da un ISI di 200 ms (2 Hz) in ordine casuale. Ogni blocco è stato ripetuto cinque volte. Ai partecipanti è stato chiesto di concentrarsi continuamente su un marchio di fissazione presentato centralmente., Queste piste di localizzatore funzionale facevano parte di altri due esperimenti di percezione del viso, pubblicati altrove (Nagy et al., 2009, 2011).

Figura 1. Stimoli campione dell’esperimento. Tutte le immagini erano in scala di grigi, uguali per dimensioni, luminanza e contrasto. Il pannello di sinistra mostra un volto, caratteristiche specifiche di genere(come capelli, gioielli ecc.) era nascosto dietro una maschera ovale. Il pannello centrale mostra un oggetto geometrico non sense del campione, mentre il pannello destro mostra la versione randomizzata di Fourier degli oggetti, usata come stimoli di controllo.,
Acquisizione e analisi dei dati
L’imaging è stato eseguito utilizzando uno scanner a testa MR 3-T (Siemens Allegra, Erlangen, Germania). Per la serie funzionale abbiamo acquisito continuamente immagini (29 fette, inclinate di 10 ° rispetto all’assiale, sequenza EPI ponderata T2*, TR = 2000 ms; TE = 30 ms; angolo di rotazione = 90°; matrici 64 × 64; risoluzione in-plane: 3 mm × 3 mm; spessore fetta: 3 mm). Immagini ad alta risoluzione sagittale T1 ponderata sono state acquisite utilizzando una sequenza EPI magnetizzazione (MP-RAGE; TR = 2250 ms; TE = 2.,6 ms; 1 mm formato voxel isotropico) per ottenere una scansione strutturale 3D (Per i dettagli, vedere Nagy et al., 2011).
Le immagini funzionali sono state corrette per il ritardo di acquisizione, riallineate, normalizzate allo spazio MNI, ricampionate a risoluzione 2 mm × 2 mm × 2 mm e smussate spazialmente con un kernel gaussiano di 8 mm FWHM (SPM8, Welcome Department of Imaging Neuroscience, London, UK; per i dettagli dell’analisi dei dati, vedere Nagy et al., 2011).
VOI Selection
In primo luogo, sono stati selezionati volumi di interessi (VOI), in base all’attività e ai vincoli anatomici (incluso il mascheramento per le regioni cerebrali rilevanti)., Le aree faccia-selettive sono state definite come un’area che mostra un’attivazione maggiore per i volti rispetto alle immagini e agli oggetti del rumore di Fourier. FFA è stato definito all’interno del giro fusiforme laterale, mentre OFA all’interno della IOG. LO è stato definito dall’Oggetto > Rumore di Fourier e contrasto delle immagini del viso, all’interno del Giro occipitale medio. La selezione VOI era basata sui contrasti T regolati con contrasto F, (p < 0.005 non corretti con una dimensione minima del cluster di 15 voxel)., I VOIS erano sferici con un raggio di 4 mm attorno all’attivazione del picco (per le singole coordinate, vedere la Tabella A1 in appendice). La varianza spiegata dal primo autovalore dei segnali in GRASSETTO era tutta al di sopra del 79%. Solo le aree dell’emisfero destro sono state utilizzate nell’attuale analisi del DCM poiché diversi studi indicano il ruolo dominante di questo emisfero nella percezione del viso (Michel et al., 1989; Sergent et al., 1992).,
Analisi di connettività efficace
La connettività efficace è stata testata da DCM-10, implementata in SPM8 toolbox (Wellcome Department of Imaging Neuroscience, London, UK), in esecuzione su Matlab R2008a (The MathWorks, Natick, MA, USA). I modelli di DCM sono definiti con connessioni endogene, che rappresentano l’accoppiamento tra regioni cerebrali (matrice A), connessioni modulatorie (matrice B) e input di guida (matrice C). Qui nella matrice A abbiamo definito le connessioni tra le regioni faccia-selettive (FFA e OFA) e LO., Immagini di volti e oggetti servivano da input di guida (matrice C) e in questa fase di analisi non abbiamo applicato alcun effetto modulatorio sulle connessioni.
La stima del modello mirava a massimizzare le stime negative di energia libera dei modelli (F) per un dato set di dati (Friston et al., 2003). Questo metodo garantisce che il model fit utilizzi i parametri in modo parsimonioso (Ewbank et al., 2011). I modelli stimati sono stati confrontati, sulla base del modello evidences p (y / m), che è la probabilità p di ottenere dati osservati y dati da un particolare modello m (Friston et al., 2003; Stephan et al., 2009)., Nel presente studio applichiamo l’approssimazione negativa dell’energia libera (energia libera variazionale) all’evidenza del registro (MacKay, 2003; Friston et al., 2007). La selezione del modello bayesiano (BMS) è stata effettuata su entrambi i disegni a effetto casuale (RFX) e fisso (FFX) (Stephan et al., 2009). BMS RFX è più resistente ai valori anomali rispetto a FFX e non presuppone che lo stesso modello spieghi la funzione per ciascun partecipante (Stephan et al., 2009). In altre parole RFX è meno sensibile al rumore., Nell’approccio RFX l’output dell’analisi è la probabilità di superamento dello spazio del modello, che è la misura in cui un modello è più propenso a spiegare i dati misurati rispetto ad altri modelli. L’altro output dell’analisi RFX è la probabilità posteriore attesa, che riflette la probabilità che un modello abbia generato i dati osservati, consentendo diverse distribuzioni per diversi modelli. Entrambi questi valori dei parametri sono ridotti dall’ampliamento dello spazio del modello (es.,, aumentando il numero di modelli), quindi si comportano in modo relativo e modelli con caratteristiche condivise e modelli non plausibili possono distorcere l’output dell’analisi. Pertanto, oltre al confronto diretto dei 28 modelli creati, abbiamo suddiviso lo spazio del modello in famiglie, con modelli di connettività simili, utilizzando i metodi di Penny et al. (2010).
Poiché diversi precedenti studi DCM indicano la stretta connessione bidirezionale tra FFA e OFA (Ishai, 2008; Gschwind et al.,, 2012) nella nostra analisi queste due aree erano sempre collegate tra loro e LO era collegato ad esse in ogni modo biologicamente plausibile. I 28 modelli rilevanti sono stati divisi in tre famiglie di modelli basate su differenze strutturali (Penny et al., 2010; Ewbank et al., 2011). La famiglia 1 contiene modelli con connessioni lineari tra le tre aree, supponendo che le informazioni fluiscano dal LO al FFA tramite l’OFA. La famiglia 2 contiene modelli con una struttura triangolare in cui LO invia l’input direttamente all’FFA e l’OFA è anche direttamente collegato all’FFA., La famiglia 3 contiene modelli, in cui le tre aree sono interconnesse, supponendo un flusso circolare di informazioni (Figura 2). Al fine di limitare il numero di modelli in questa fase dell’analisi, gli input hanno modulato esclusivamente l’attività delle loro aree di ingresso. Le tre famiglie sono state confrontate da un BMS design casuale.
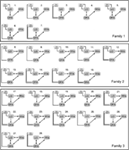
Figura 2. I 28 modelli analizzati. Le linee nere segnano la divisione tra le tre famiglie, avendo diverse strutture A matrice. Per i dettagli, vedere la sezione ” Materiali e metodi.,”
In secondo luogo, i modelli della famiglia vincitrice sono stati ulteriormente elaborati creando ogni modello plausibile con connessioni modulatorie, applicando tre vincoli. Innanzitutto, sia le facce che gli oggetti modulano almeno una connessione inter-areale. In secondo luogo, in caso di collegamenti bidirezionali gli ingressi modulatori hanno un effetto su entrambe le direzioni. Terzo, se face fornisce un input diretto in OFA, assumiamo che moduli sempre anche la connessione OFA–FFA (vedi Tabella A2 in Appendice). Questi modelli sono stati inseriti in una seconda analisi BMS casuale a livello familiare., Infine, i membri della sottofamiglia vincitrice sono stati inseriti in un terzo BMS per trovare un singolo modello con la più alta probabilità di superamento.
Risultati
La selezione del modello bayesiano è stata utilizzata per decidere quale famiglia di modelli spiega meglio i dati misurati. Come mostrano i nostri risultati, la terza famiglia ha superato le altre due, con una probabilità di superamento di 0,995 rispetto allo 0,00 della prima famiglia e allo 0,004 della seconda famiglia (Figure 3A,B)., La famiglia del modello vincitore (Famiglia 3; Figura 2, in basso) contiene 12 modelli, aventi connessioni tra LO e FFA, OFA e FFA, e LO e OFA, ma che differiscono nella direzionalità delle connessioni e nel luogo di ingresso alla rete.

Figura 3. Risultati di BMS RFX a livello di famiglie. (A) Vengono mostrate le probabilità attese del confronto basato sulla famiglia, con le probabilità di superamento congiunto (B).,
Come secondo passo, tutti i possibili modelli modulatori sono stati progettati per i 12 modelli della famiglia 3 (vedi Tabella A2 in appendice; Materiali e metodi per i dettagli). Ciò ha portato a 122 modelli, che sono stati inseriti nell’analisi casuale della famiglia BMS, utilizzando 12 sotto-famiglie. Come è visibile dalle figure 4A, B, la sottofamiglia del modello 4 ha superato le altre sottofamiglie con una probabilità di superamento di 0,79. Come terzo passo, i modelli all’interno del vincitore sub-famiglia 4 sono stati inseriti in un effetto casuale BMS. La figura 5 presenta le 18 varianti testate del Modello 20., Il modello con la più alta probabilità di superamento (p = 0,75) era il modello 4 (vedi Figura 6). Ciò significa che il modello vincitore contiene connessioni bidirezionali tra tutte le aree e gli ingressi faccia e oggetto, sorprendentemente, entrambi entrano nel LO. Inoltre, le facce hanno un effetto modulante sulla connessione tra LO e FFA, mentre gli oggetti modulano la connessione tra LO e OFA.

Figura 4. Risultati di BMS RFX a livello di sotto-famiglie., (A) Vengono mostrate le probabilità attese del confronto basato sulla famiglia, con le probabilità di superamento congiunto (B).

Figura 5. Modelli di sottofamiglia 4. Tutti i modelli hanno lo stesso DCM.Una struttura (identica al modello 20 nella famiglia 3), DCM.B struttura differisce da modello a modello. Le frecce tratteggiate simboleggiavano l’effetto modulatorio del viso, mentre le frecce quadrate tratteggiate mostrano la modulazione dell’oggetto.
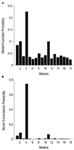
Figura 6., Risultati di BMS all’interno della sottofamiglia 4. (A) Vengono mostrate le probabilità attese del confronto basato sulla famiglia, con le probabilità di superamento congiunto (B).
Per analizzare le stime dei parametri del modello vincitore attraverso il gruppo di soggetti è stata utilizzata un’approssimazione a effetto casuale. Tutte le stime massime specifiche del soggetto a posteriori (MAP) sono state inserite in un t-test per singoli mezzi e testate contro 0 (Stephan et al., 2010; Desseilles et al., 2011). I risultati indicizzati con un asterisco nella Figura 7 differivano significativamente da 0 (p < 0.,05).
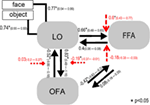
Figura 7. La struttura del modello vincitore. Linee semplici indicano gli stimoli di input dell’oggetto e del viso al sistema (DCM.C). Le frecce nere mostrano i collegamenti interregionali (DCM.A) mentre le frecce rosse indicano i collegamenti modulatori (DCM.B): la modulazione del volto è indicata con frecce tratteggiate, mentre la modulazione dell’oggetto è indicata con frecce tratteggiate a testa quadrata. Sono illustrate le medie a livello di gruppo delle stime delle MAPPE e gli intervalli di confidenza del 95%., Le medie sono state testate su 0 e i risultati significativi sono indicati con * if p < 0.05.,
Discussione
Il principale risultato del presente connettività effettiva studio suggeriscono che (a) LO è collegato direttamente alla OFA–FFA volto-sistema di elaborazione tramite la connessione bidirezionale per entrambe le aree; (b) non faccia e la faccia ingressi sono mescolati a livello di occipito-temporale aree e inserire il sistema tramite LO; (c) il viso di ingresso ha un effetto modulante sul LO e FFA connessione, mentre oggetto di input modula lo e DI connessione in modo significativo.
Il ruolo di LO nella percezione degli oggetti è ben noto da studi precedenti (Malach et al.,, 1995; Grill-Spector et al., 1998a, b, 2000; Lerner et al., 2001, 2008). Tuttavia, nonostante gli studi precedenti di solito trovato una maggiore attività per oggetti complessi, così come per i volti in LO, l’area è di solito associato con gli oggetti e relativamente meno importanza è attribuita al suo ruolo in face-processing. Nel presente studio, un’efficace analisi della connettività ha posizionato lo nella rete principale della percezione del viso. Il legame diretto tra OFA e FFA è stato dimostrato in precedenza sia funzionalmente che anatomicamente (Gschwind et al., 2012)., Tuttavia, poiché non ci sono dati attuali disponibili sul ruolo di LO in questo sistema, lo abbiamo collegato alle altre due regioni in diversi modi plausibili.
Il primo BMS casuale ha mostrato che nella famiglia del modello vincitore LO è interconnesso sia con FFA che con OFA e le connessioni sono bidirezionali. Pertanto, evidenzia che LO può avere una connessione strutturale diretta con FFA., Con la modellazione di tutti i possibili effetti modulatori abbiamo scoperto che una sottofamiglia di modelli ha vinto, in cui sia gli input oggetto che faccia entrano nel sistema tramite LO, supponendo che LO svolga un ruolo generale e importante nella regione di input. Da precedenti studi di connettività funzionale, tutti hanno iniziato l’analisi della rete di elaborazione del viso a livello di IOG, corrispondente a OFA (Fairhall e Ishai, 2007; Ishai, 2008; Cohen Kadosh et al., 2011; Dima et al., 2011; Foley et al., 2012) non sorprende che abbiano trascurato il ruolo significativo di LO., Tuttavia, i volti sono in realtà una categoria distinta di oggetti visivi, suggerendo che i neuroni sensibili agli oggetti e alle forme dovrebbero essere attivati, almeno in una certa misura, anche dai volti. Infatti, studi unicellulari di primati non umani suggeriscono che la corteccia temporale inferiore, l’omologo proposto di LO umano nel cervello macaco (Denys et al., 2004; Sawamura et al., 2006) ha neuroni sensibili anche ai volti (Perrett et al., 1982, 1985; Desimone et al., 1984; Hasselmo et al., 1989; Young e Yamane, 1992; Sugase et al., 1999)., La connessione intima di LO a OFA e FFA, suggerita dal presente studio potrebbe sottolineare il fatto che volti e oggetti non sono elaborati completamente separatamente nel percorso visivo ventrale, una conclusione supportata anche da recenti dati di imaging funzionale (Rossion et al., 2012). L’effetto modulatorio dell’input facciale sulla connessione LO-FFA suggerisce che LO deve svolgere un ruolo nell’elaborazione delle facce, molto probabilmente legato alla precedente elaborazione strutturale delle facce, un compito precedentemente assegnato principalmente a OFA (Rotshtein et al., 2005; Fox et al., 2009)., Infine, i parametri a livello di gruppo del modello vincitore mostrano che il legame tra LO, OFA e FFA è principalmente gerarchico e le connessioni di feedback da FFA verso OFA e LO svolgono un ruolo più debole nel sistema, almeno durante l’attività di fissazione applicata.
In conclusione, modellando l’effettiva connettività tra le aree rilevanti per il viso e LO suggeriamo che LO svolge un ruolo significativo nell’elaborazione dei volti.,
Dichiarazione sul conflitto di interessi
Gli autori dichiarano che la ricerca è stata condotta in assenza di relazioni commerciali o finanziarie che potrebbero essere interpretate come un potenziale conflitto di interessi.
Riconoscimenti
Questo lavoro è stato sostenuto dalla Deutsche Forschungsgemeinschaft (KO 3918/1-1) e dall’Università di Ratisbona. Vorremmo ringraziare Ingo Keck e Michael Schmitgen per la discussione.
Campbell, R. (2011). Speechreading e il modello Bruce-Young di riconoscimento facciale: primi risultati e recenti sviluppi. Fr. J. Psicol. 102, 704–710.,
Pubmed Abstract | Pubmed Full Text/CrossRef Full Text
Fairhall, SL, and Ishai, A. (2007). Connettività efficace all’interno della rete corticale distribuita per la percezione del viso. Cereb. Cortex 17, 2400-2406.
Pubmed Abstract | Pubmed Full Text/CrossRef Full Text
Hoffman, E. A., and Haxby, JV (2000). Rappresentazioni distinte dello sguardo dell’occhio e dell’identità nel sistema neurale umano distribuito per la percezione del viso. NAT. Neurosci. 3, 80–84.
Pubmed Abstract / Pubmed Full Text / CrossRef Full Text
Kourtzi, Z.,, e Kanwisher, N. (2001). Rappresentazione della forma dell’oggetto percepito dal complesso occipitale laterale umano. Scienza 293, 1506-1509.
Pubmed Abstract | Pubmed Full Text/CrossRef Full Text
MacKay, D. J. C. (2003). Teoria dell’informazione, inferenza e algoritmi di apprendimento. Cambridge: Cambridge University Press.
Nasanen, R. (1999). Larghezza di banda di frequenza spaziale utilizzata nel riconoscimento di immagini facciali. Visione Res. 39, 3824-3833.
Pubmed Abstract / Pubmed Full Text / CrossRef Full Text
Rossion, B., Schiltz, C. e Crommelinck, M., (2003b). Le “aree facciali” occipitali e fusiformi destra funzionalmente definite discriminano romanzo da visi visivamente familiari. Neuroimage 19, 877-883.
CrossRef Full Text
Sawamura, H., Orban, GA e Vogels, R. (2006). La selettività dell’adattamento neuronale non corrisponde alla selettività della risposta: uno studio monocellulare del paradigma di adattamento fMRI. Neurone 49, 307-318.
Pubmed Abstract / Pubmed Full Text / CrossRef Full Text
















Lascia un commento