№
![]()


![]()


![]()

amundsenは、データと対話する際のデータアナリスト、データ科学者、エンジニアの生産性を向上させるためのデータ検出およびメタデータエンジンです。 では本日より索引データリソース(テーブル、ダッシュボートなど。)および使用パターンに基づいてページランクスタイルの検索を行う(例えば、, 高照会されるテーブルまでより早く低照会される。 データのためのGoogle検索として考えてください。 このプロジェクトの名前は、ノルウェーの探検家ロアルド-アムンセンにちなんで名付けられました。

アムンセンはLF AI&Data Foundationによってホストされています。 これには、三つのマイクロサービス、一つのデータ取り込みライブラリ、一つ
- amundsenfrontendlibrary:Reactフロントエンドを持つFlaskアプリケーションであるフロントエンドサービス。,

- amundsensearchlibrary:検索機能にElasticsearchを活用した検索サービスは、フロントエンドのメタデータ検索を強化するために使用されます。

- amundsenmetadatalibrary:Neo4jまたはApache Atlasを永続層として利用して、さまざまなメタデータを提供するメタデータサービスです。

- amundsendatabuilder:メタデータグラフと検索インデックスを構築するためのデータ取り込みライブラリ。 ユーザーがデータを読み込みをpythonスクリプトに図書館は空気の流DAGの輸入の図書館があります。,

- amundsencommon:Amundsen Common libraryは、Amundsenのマイクロサービス間で共通のコードを保持します。

- amundsengremlin:Amundsen Gremlinライブラリは、モデルオブジェクトをgremlinの頂点とエッジに変換するために使用されるコードを保持します。 AWS Neptuneバックエンドにデータをロードするために使用されます。

- amundsenrds:Amundsenrdsには、AmundsenのメタデータバックエンドストアとしてリレーショナルデータベースをサポートするORMモデルが含まれています。 ORMモデルのスキーマは、データビルダーモデルのロジックに従います。, Amundsenrdsは、リレーショナルデータベースを使用したメタデータの格納と取得のために、databuilderおよびmetadatalibraryで使用されます。

ホームページ¶
- Python=3.6 3.7
- のノード=v10はv12(v14が互換性の問題)
- npm>=6
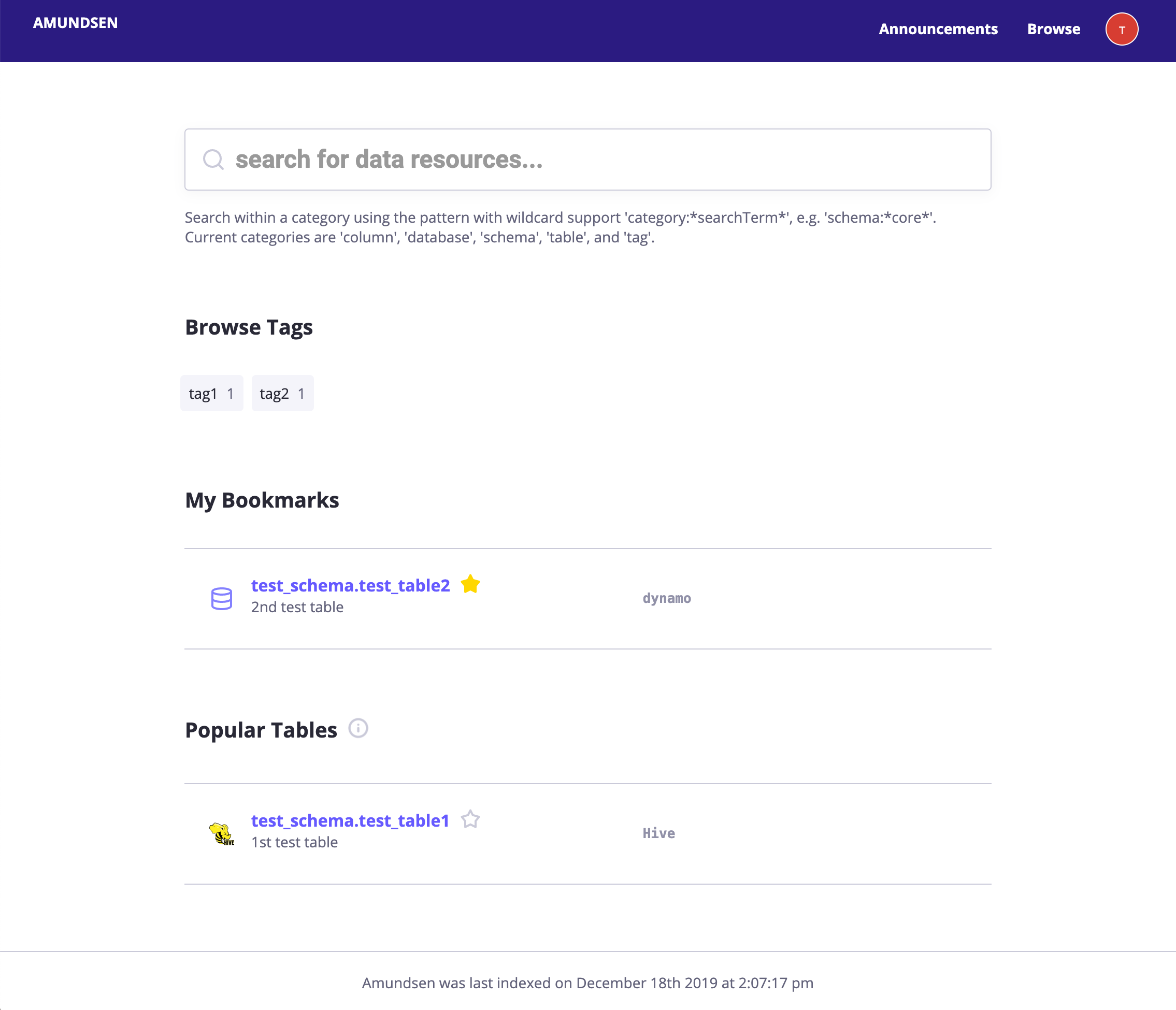
- ランディングページ:アムンセンのランディングページ1を含む。 検索バー;2., よく使用されるテーブル;
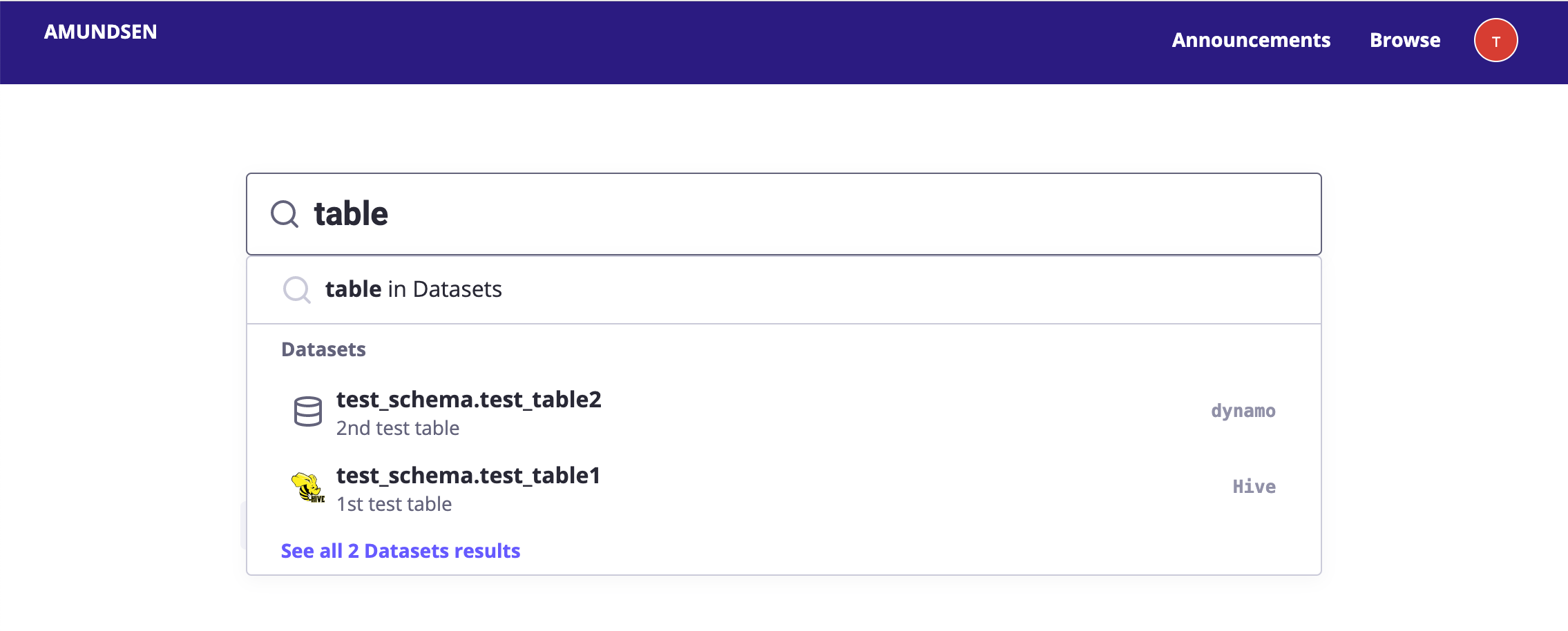
- 検索プレビュー:入力時にインライン検索結果を参照してください
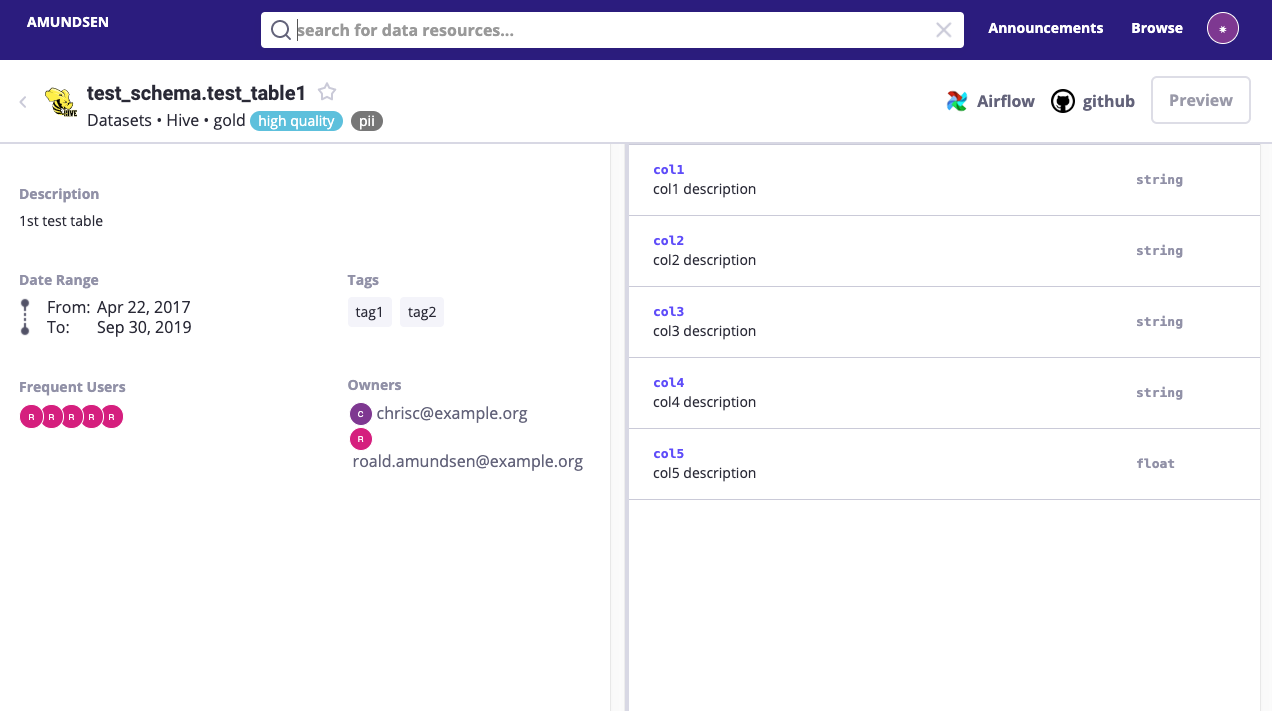
- テーブル詳細ページ:ハイブ/赤方偏移テーブルの視覚化
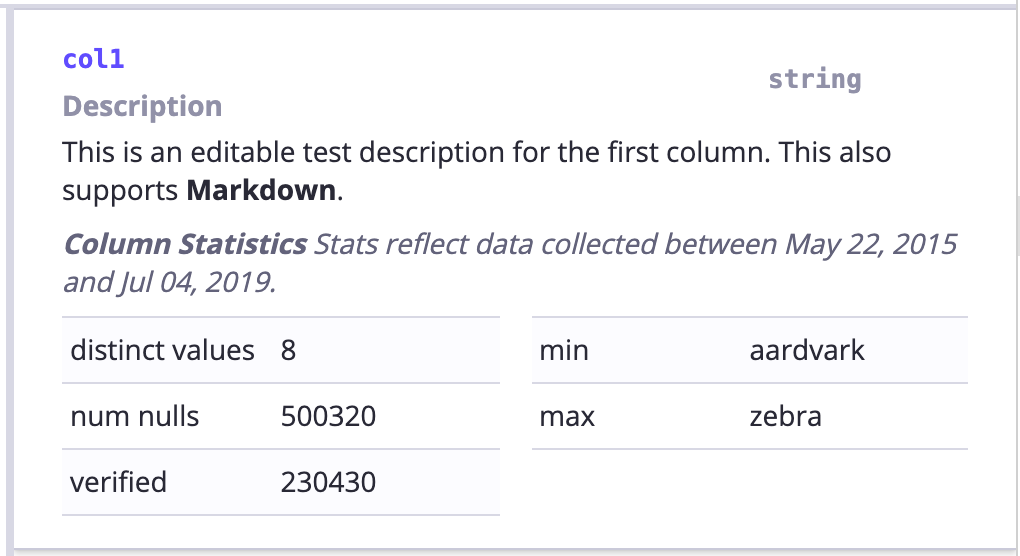
- 列の詳細:オプションの統計表示を含むhive/redshiftテーブルの列の視覚化
- データプレビューページ:apacheスーパーセットまたは他のデータ視覚化ツールと統合できるテーブルデータプレビューの視覚化。,
- テーブル(データベースから)
- 人(HRシステムから)
- ダッシュボード
- Amazon Athena
- Amazon Glueとその上に構築されているもの(進行中の作業であるDatabricks Deltaなど)。,
- Amazon Redshift
- Apache Cassandra
- Apache Druid
- Apache Hive
- CSV
- Delta Lake
- Google BigQuery
- IBM DB2
- Microsoft SQL Server
- MySQL
- Oracle(dbapiまたはsql_alchemyを介して)
- PostgreSQL
- soon
- vertica
- Snowflake
- Mode Analytics
- Redash
- Tableau
- Apache Airflow
- Apacheスーパーセット
- Amundsen-Lyftのデータディスカバリー&metadata engine(April2019)
- Software Engineering Daily podcast on Amundsen(April2019)
- Lyftがデータディスカバリーをどのように推進するか(July2019)
- Lyftでデータディスカバリーを解決するためのデータエンジニアリングポッドキャスト(Aug2019)
- オープンソーシングAmundsen:データ検出とメタデータプラットフォーム(Oct2019)
- edmundsのsam shusterによるプログラムによる説明により、amundsenにデータ品質を追加します。,Landscape
- LyftのAmundsen:組み込みの信頼によるデータ検出
- コマンドラインからデータを検索して整理する方法
- Bagelcodeのデータ検出プラットフォーム
- データチームのためのカタログツール
- データ検出プラットフォームとオープンソースソリューションの概要
- SEEKのAmundsenによるAWSでのデータ検出のハッキング
- Googleクラウドへのアムンセンのデプロイ
- ステップバイステップガイドアムンセンをデプロイするプラットフォーム
- Bang&Olufsen
- Brex
- Cameo
- Cimpress Technology
- Coles Group
- Convoy
- Date Sprints
- Dcard
- 献身的な健康
- DHIグループ
- pubg
- rapid
- rea group
- Remitly
- Square
- Wetransfer
- Workday
文書¶
要件¶
ユーザインタフェース¶
ただの模擬画像のみと実証目的です。
コミュニティに参加
助けが欲しいか、助けたいですか?Slackチャンネルに参加するには、ヘッダーのボタンを使用します。 貢献も歓迎よりも多くのものです! で説明したようにCONTRIBUTING.md 貢献する方法はたくさんありますが、新機能やバグ修正、FAQエントリ、バグレポート、経験を共有するブログ投稿などのドキュメントを含むコードである必 アムンセンを前進させるのに役立つ また、セキュリティに係る脆弱性従ってください。,
はじめに¶
Amundsenのデフォルトバージョンをダミーデータでブートストラップするためのクイックスタートについては、Amundsenのインストールドキュメントを
アーキテクチャの概要¶
アムンゼンアーキテクチャの概要をご覧ください。
サポートされているエンティティ¶
サポートされている統合¶
テーブルコネクタ¶
amundsenは、dbapiまたはsql_alchemyインターフェイス(ほとんどのDbが提供する)を提供する任意のデータベースに接続することもできます。,
ダッシュボードコネクタ¶
ETLオーケストレーション¶
BI Vizツール¶
インストール¶
インストールガイドラインをご覧くださいamundsenをインストールする方法について。
ロードマップ¶
アムンセンの今後のロードマップ項目に興味がある場合は、ロードマップをご覧ください。,
ブログ記事とインタビュー
コミュニティミーティング¶
コミュニティミーティングは、毎月第一木曜日に太平洋午前9時、東部正午、中央ヨーロッパ時間午後6時に開催されます。, 参加するためのリンク
今後の会議&注意事項¶
この文書では、会議の数週間前に次の会議の正確な日付と議題を確認できます。
過去のすべての会議のメモはこちらからご覧いただけます。
誰がアムンセンを使用していますか?√
今日Amundsenを使用している組織のリストは次のとおりです。 あなたの組織がAmundsenを使用している場合は、PRを提出してこのリストを更新してください。,Bagelcode
apache2.,0ライセンス。
















コメントを残す