 GitHubでソースを表示
GitHubでソースを表示このチュートリアルでは、CIFAR画像を分類するための単純な畳み込みニューラルネットワーク(CNN) このチュートリアルではKeras Sequential APIを使用しているため、モデルの作成とトレーニングには数行のコードが必要です。,
Import TensorFlow
import tensorflow as tffrom tensorflow.keras import datasets, layers, modelsimport matplotlib.pyplot as pltCIFAR10データセットのダウンロードと準備
CIFAR10データセットには60,000個のカラー画像が10個のクラスに含まれ、各クラスに6,000個の画像が含まれています。 のデータセットに分かれて50,000研修画像10,000試験ます。 クラスは相互に排他的であり、それらの間に重複はありません。
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz170500096/170498071 - 11s 0us/step
データの検証
データセットが正しく見えることを確認するには、トレーニングセットの最初の25個の画像をプロットし、各画像の下に,

畳み込み基底を作成します
以下の6行のコードは、Conv2D層とMaxPooling2D層のスタックである共通のパターンを使用して畳み込み基底を定義します。入力として、CNNはバッチサイズを無視して、形状のテンソル(image_height、image_width、color_channels)を取ります。 これらの次元に慣れていない場合、color_channelsは(R、G、B)を参照します。 この例では、cifarイメージの形式であるshape(32、32、3)の入力を処理するようにCNNを設定します。 これを行うには、引数input_shapeを最初のレイヤーに渡します。,
これまでのモデルのアーキテクチャを表示しましょう。
model.summary()上記では、すべてのConv2DおよびMaxPooling2Dレイヤーの出力が形状(高さ、幅、チャンネル)の3Dテンソルであることがわかります。 幅と高さの寸法は、ネットワークを深くするにつれて縮小する傾向があります。 各Conv2D層の出力チャンネル数は、最初の引数(例えば、32または64)によって制御されます。 通常、幅と高さが縮小するにつれて、各Conv2Dレイヤーに出力チャンネルを追加する余裕が(計算上)あります。,
上に緻密なレイヤーを追加
モデルを完成させるために、畳み込み基底(形状(4、4、64))から最後の出力テンソルを分類を実行するために一つ以上の密なレイヤーにフィードします。 高密度層は入力としてベクトル(1D)を取り、現在の出力は3Dテンソルです。 まず、3D出力を1Dに平ten化(または展開)し、その上に一つ以上の高密度レイヤーを追加します。 CIFARには10個の出力クラスがあるため、10個の出力を持つ最終的な高密度レイヤーを使用します。
model.add(layers.Flatten())model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10))モデルの完全なアーキテクチャは次のとおりです。,
model.summary()ご覧のとおり、(4,4,64)出力は、二つの密な層を通過する前に、形状(1024)のベクトルに平tened化されました。
モデルをコンパイルしてトレーニングする
モデルを評価する
313/313 - 1s - loss: 0.8840 - accuracy: 0.7157
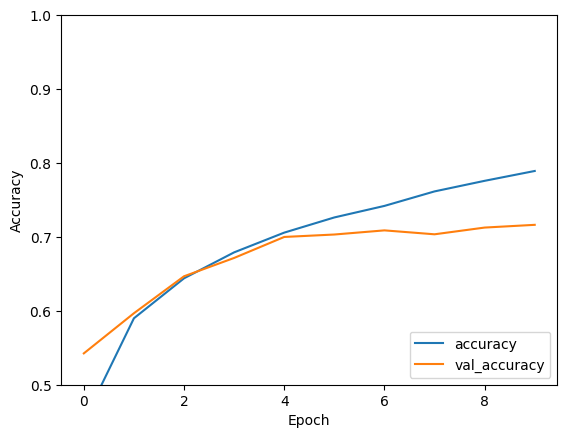
print(test_acc)















コメントを残す